使用 Nsight Compute 对算子进行优化
pid=113949971
本文是 Analysis-Driven Optimization: Finishing the Analysis with NVIDIA Nsight Compute 系列文章(共三部分)的阅读笔记,对学习 Nsight Compute 这一 profiling 工具很有帮助,同时也推荐作者的另一篇 Using Nsight Compute to Inspect your Kernels 作为入门
作者基于一个构造出的 Workload,使用 Nsight Compute 分析不同版本代码实现的性能瓶颈并指导优化。
Workload
三维矩阵求平均 + 矩阵乘法
1 | |
笔者机器 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz (104核)
Tesla V100S-PCIE-32GB CUDA 12.2 驱动 535.54.03
CPU 版本(并行 0.362923s / 非并行 4.71439s)
1 | |
GPU 版本一(2.37139s)
grid = 1
block = 1024
1 | |
1 | |
问题:gridDim=1,SM 利用率极低,也可以直接在 Nsight Compute 的 SM 利用率中看到
GPU 版本二(2.37139s -> 0.083069s)
很容易想到 gridDim 可以对应 inp.dim0 维度的并行,提速 30 倍
1 | |
GPU 版本三(0.083069s -> 0.021241s)
优化访存,提速四倍
(接下来开始大量使用 Nsight Compute)
GPU Speed of Light
本栏指出
[Warning] This kernel exhibits low compute throughput and memory bandwidth utilization relative to the peak performance of this device. Achieved compute throughput and/or memory bandwidth below 60.0% of peak typically indicate latency issues. Look at Scheduler Statistics and Warp State Statistics for potential reasons.
Scheduler Statistics 一栏的 Issue Slot Utilization Rule 指出
[Warning] Every scheduler is capable of issuing one instruction per cycle, but for this kernel each scheduler only issues an instruction every 6.8 cycles. This might leave hardware resources underutilized and may lead to less optimal performance. Out of the maximum of 16 warps per scheduler, this kernel allocates an average of 16.00 active warps per scheduler, but only an average of 0.69 warps were eligible per cycle. Eligible warps are the subset of active warps that are ready to issue their next instruction. Every cycle with no eligible warp results in no instruction being issued and the issue slot remains unused. To increase the number of eligible warps either increase the number of active warps or reduce the time the active warps are stalled.
scheduler 平均每 6.8 个 cycle 才能 issue 一个指令,参考 CUDA C Programming Guide Arithmetic Instructions 一节,7.x SM 每 cycle 可以执行 64 个 float32 加/乘指令,每个 scheduler 对应 1/4 个 SM,最大 16 个 warp,意味着每个 CUDA Core 每个 cycle 可以完成一个 float32 add/mul/add-mul,这和 16 个 warp 每 6.8 个 cycle 执行一个指令相去甚远。上面还指出,甚至有 31% 的 cycle 没有任何 warp 处于可以接受指令的状态
Warp State Statistics
本栏的 Stall LG Throttle Rule 指出
On average, each warp of this kernel spends 89.6 cycles being stalled waiting for the L1 instruction queue for local and global (LG) memory operations to be not full. Typically, this stall occurs only when executing local or global memory instructions extremely frequently. Avoid redundant global memory accesses. Try to avoid using thread-local memory by checking if dynamically indexed arrays are declared in local scope, of if the kernel has excessive register pressure causing by spills. If applicable, consider combining multiple lower-width memory operations into fewer wider memory operations and try interleaving memory operations and math instructions. This stall type represents about 76.0% of the total average of 117.9 cycles between issuing two instructions.
每个平均 warp 都有 89.6 个 cycle 在等待 L1 instruction queue 有空间,可能的触发条件:global 访存过多、使用了 thread local 内存(应当避免)、register 太多导致 spill
Question: 什么是 L1 instruction queue
GPT:
- Local/Global Instruction Queue: When warps execute memory instructions (reading from or writing to memory), these instructions are placed in a queue before they can be processed. NVIDIA GPU architectures have separate instruction queues for different kinds of memory operations. In this case, “local/global” refers to the queue for memory operations that access either local memory (thread-specific memory) or global memory (accessible by all threads).
- Not Full: For an instruction to be placed in the queue, there must be space available. If the queue is full, new instructions must wait until there is room, leading to stalls.
Question: MIO throttle、LG throttle、Tex throttle 分别是什么
https://stackoverflow.com/a/66569433
The MIO is a partition in the NVIDIA SM (starting in Maxwell) that contains execution units shared between the 4 warp schedulers or slower math execution units (e.g. XU pipe).
Instructions issued to these execution units are first issued into instruction queues allowing the warp schedulers to continue to issue independent instructions from the warp. If a warp’s next instruction is to an instruction queue that is full then the warp is stalled until the queue is not full and the instruction can be enqueued. When this stall occurs the warp will report a throttle reason based upon the instruction queue type. The mapping of instruction queues to pipes differs between chips. This is the general mapping.
- mio_throttle (ADU, CBU, LSU, XU)
- lg_throttle (LSU)
- lg_throttle is used if MIO instruction queue reaches a watermark for local/global instructions. Throttling local/global instructions early allows SM to continue to issue shared memory instructions when L1 backpressure due to local/global L1 misses.
- tex_throttle (TEX, FP64 on non-*100 chips, Tensor on TU11x)
If the warp’s next instruction to issue is to a sub-partition specific execution unit (FMA, ALU, Tensor, FP64 (*100 GPUs) then the stall reason is math_throttle.
Question: Roofline chart 指出虽然 Performance (FLOP/s) 上升,但相比于版本二的 arithmetic intensity 下降了,为什么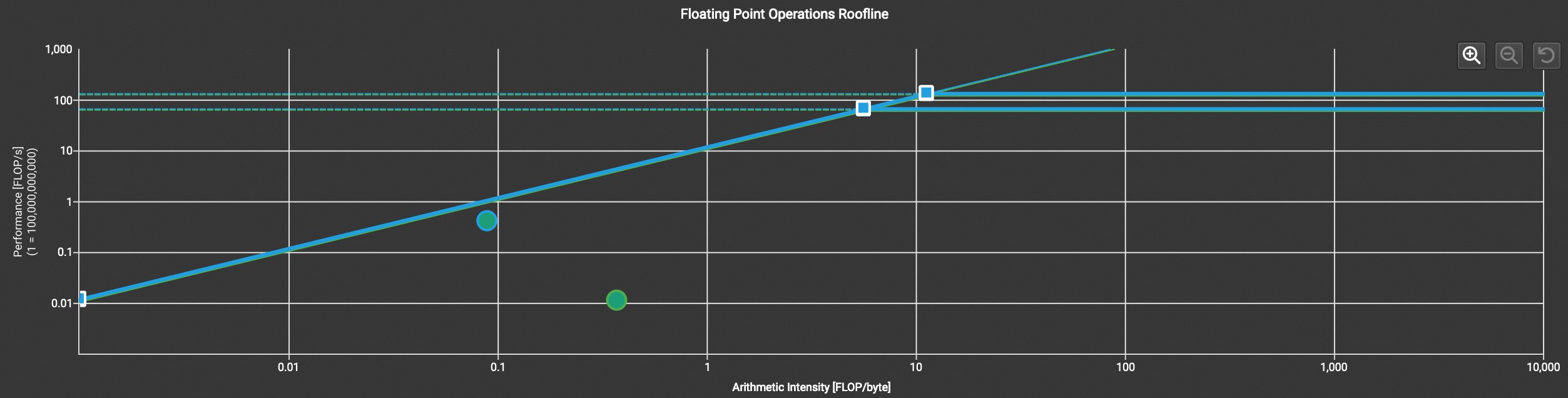
(我的理解)SM 利用率大幅提高提供了更高的 Performance,但也导致 SM 的 L1 instruction queue 打满,使得算子更加偏向 mem bound,对应 arithmetic intensity 下降。原先的算子没有到达 roofline 的 1%,新的实现虽然降低 itensity 导致上限降低,但是达到了 40% 的理论极限
Source Counters
Scheduler Statistics 一栏推荐我们看 Warp State Analysis 与 Source Counters,Source Counters 指出
This kernel has uncoalesced global accesses resulting in a total of 939524096 excessive sectors (78% of the total 1209008128 sectors). Check the L2 Theoretical Sectors Global Excessive table for the primary source locations. The CUDA Programming Guide has additional information on reducing uncoalesced device memory accesses.
Question: 什么是 sector
https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html
Aligned 32 byte-chunk of memory in a cache line or device memory. An L1 or L2 cache line is four sectors, i.e. 128 bytes. Sector accesses are classified as hits if the tag is present and the sector-data is present within the cache line. Tag-misses and tag-hit-data-misses are all classified as misses.
就是 32 byte 的一次访问
Question:什么是 wavefront
https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html
Unique “work package” generated at the end of the processing stage for requests. All work items of a wavefront are processed in parallel, while work items of different wavefronts are serialized and processed on different cycles. At least one wavefront is generated for each request.A wavefront is the maximum unit that can pass through that pipeline stage per cycle. If not all cache lines or sectors can be accessed in a single wavefront, multiple wavefronts are created and sent for processing one by one, i.e. in a serialized manner. Limitations of the work within a wavefront may include the need for a consistent memory space, a maximum number of cache lines that can be accessed, as well as various other reasons. Each wavefront then flows through the L1TEX pipeline and fetches the sectors handled in that wavefront. The given relationships of the three key values in this model are requests:sectors is 1:N, wavefronts:sectors 1:N, and requests:wavefronts is 1:N.
A wavefront is described as a (work) package that can be processed at once, i.e. there is a notion of processing one wavefront per cycle in L1TEX. Wavefronts therefore represent the number of cycles required to process the requests, while the number of sectors per request is a property of the access pattern of the memory instruction for all participating threads. For example, it is possible to have a memory instruction that requires 4 sectors per request in 1 wavefront. However, you can also have a memory instruction having 4 sectors per request, but requiring 2 or more wavefronts.
(我的理解)一个 cycle 能处理完的数据量
Memory Workload Analysis
本栏指出从 Device 到 L2 的吞吐量达到理论上限的 40%
更重要的是,观察 L1/TEX 相关指标,Global Load 共发送 67M request / instruction,结果却引起了 1.2B 的 sector 读取(注意 request 是对于一整个 warp 来说的,因此 sector 可以大于 request)(这里的 sector 和 memory transaction 我的理解是一个意思),Sectors/Req 达到 17.77(最坏情况可以达到 warp size,32)
Question: request 与 sector 的关系?
What’s the difference between ‘wavefronts’ and ‘sectors/Req’?
When an SM executes a global/local/shared memory instruction for a warp, a single request is sent to L1TEX. This request communicates the information for all participating threads of this warp (up to 32 threads). For local and global memory, based on the access pattern and the participating threads, the request requires to access a number of cache lines, and sectors within these cache lines.
CUDA C Programming Guide 5.3.2
Global memory resides in device memory and device memory is accessed via 32-, 64-, or 128-byte memory transactions. These memory transactions must be naturally aligned: Only the 32-, 64-, or 128-byte segments of device memory that are aligned to their size (i.e., whose first address is a multiple of their size) can be read or written by memory transactions.When a warp executes an instruction that accesses global memory, it coalesces the memory accesses of the threads within the warp into one or more of these memory transactions depending on the size of the word accessed by each thread and the distribution of the memory addresses across the threads. In general, the more transactions are necessary, the more unused words are transferred in addition to the words accessed by the threads, reducing the instruction throughput accordingly. For example, if a 32-byte memory transaction is generated for each thread’s 4-byte access, throughput is divided by 8.
我们可以在代码中进一步确认这一访存问题的来源
Page Source
在右侧统计栏点击右键打开所有指标,可以观察到大部分的 warp stall 都来自于 v1 += input[k*M*L+idx*M+i]; 这行,同时从 L2 Theoretical Sectors Global Excessive 以及 L2 Theoretical Sectors Global 可以看出,有 90% 左右的 sector 内容是未被利用的,这引导我们优化此行的访存方式
版本三代码
这里给出的改进是将 block 的一部分放到矩阵行维度来并行,具体来说 thread 0-31 处理矩阵某行的第 32i + idx(0-31) 列,这样 32 个 thread 需要 32 个 float,可以填满一个 32 byte 的 memory txn。而余下的 block size 保留在矩阵行维度的并行,即一个 2D block (32, 32)
可以看到,解决访存瓶颈后,我们在 arithmetic intensity 上有所前进,也因此得到了更高的天花板,当前 kernel 达到了显卡 fp32 上 1% 的 peak performance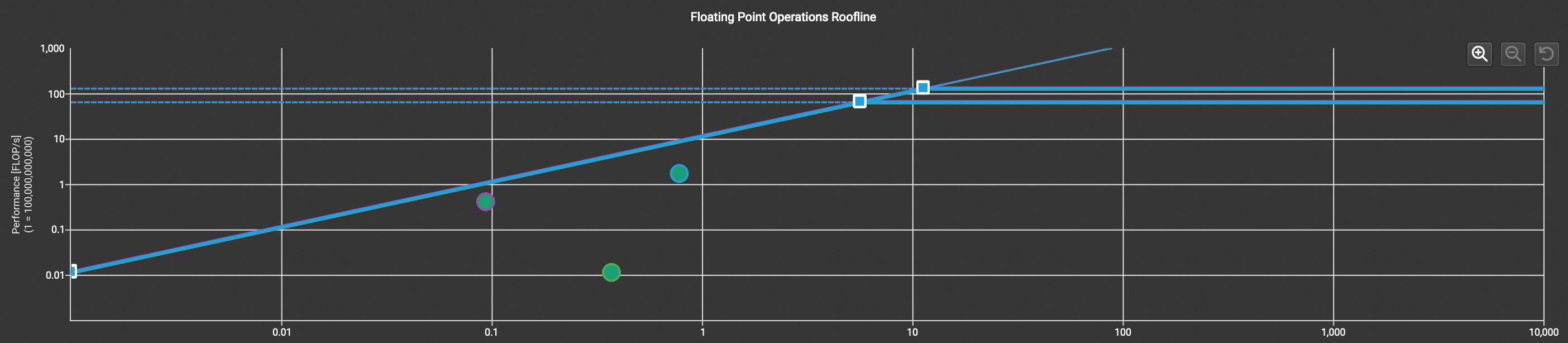
查看 Sector/Req,这次做到了 4.00,完美
1 | |
GPU 版本四(0.021241s -> 0.011824s)
继续优化访存,提速一倍
之前版本中 warp 中的 thread 每次访问矩阵不同行的相同列,这些列空间并不连续,导致 memory transaction 拿到的数据利用率很低
Question:虽然第一次访问效率很低,但这些数据就已经在 cache 了,那下一次访问效率就高了吧?
(和下面这个本质是相同的问题)
Question: 我正在用 CUDA 处理一个矩阵,每次读入一个 2D block = nm,对应矩阵的一个 nm 的子矩阵,每次向右移动 m 个单位,走完一行后向下移动 n 个单位,这样可以使得每个 memory transaction 读入的数据都是完全被需要的,但如果我换一种访问方式,比如说,39 的矩阵,2D block 大小为 33,分三次访问完这个矩阵,0 号线程三次分别访问 0,0 0,3 0,6 三个位置,1 号线程三次分别访问 0,1 0,4 0,7 三个位置,这样的话,虽然第一次读入的 memory 中不是所有的数据都被这一次访问需要,但它们可能被下一次访问需要,请问这样能获得与我最开始介绍的访问方式相似的效率吗
GPT: 在 CUDA 中处理矩阵时考虑 memory efficiency 是非常重要的,因为内存访问模式对整体性能有很大的影响。在 GPU 中,内存是通过更大的块(称为 memory transactions)读取的,而并非单个元素。这些块通常是 32 或 128 字节。当一个 warp(32 个线程)请求数据时,最理想的情况是所有线程读取的数据位于同一个或者几个连续的 memory transactions 中。这种情况称为 memory coalescing,它能够最大化 memory bandwidth 的利用率。
Question1: 我总结一下你的回答,看我的理解是否正确。第二种访问方式中,我的想法是虽然某些访问无法利用 memory coalescing,但后续的访问需要的内容可能已经在 L1 cache 了,我因此认为这有可能实现与第一种访问方式类似的性能。你的解释是我想要的 L1 cache 中的数据在后续访问时可能已经失效了,对吗?
GPT: 是的,你的理解基本上是正确的。在第二种访问方式中,你提到的某些访问可能无法利用 memory coalescing,但你期望后续访问时,所需的数据已经由于之前的访问而存在于 L1 cache 中。这确实是一个可能的情况,而且理论上可以减少对全局内存的访问次数,提高性能。
然而,我提到的是,在一些情况下,L1 cache 中的数据可能因为缓存替换策略被逐出,特别是在高度并行的环境下,多个 warp 会同时进行内存访问,可能导致缓存行频繁被替换。如果每次访问的数据集合足够大,以至于不能完全被缓存,或者内存访问模式导致缓存行被频繁替换,那么预期中的 cache hit 可能会降低,从而影响性能。
Question2: 我想到的另一种可能是某个 SM 不一定总是执行同一个 warp 直到它处理完所有数据,有可能交替执行 block 内的多个 block,从而导致 L1 cache 失效,这种可能性也会导致第二种访问方式低效,对吗?
GPT: 由于 SM 上有限的缓存资源,如 L1 cache 和 shared memory,同时存在的多个 block 和 warp 可能会争夺这些资源。当 SM 在不同的 warps 间频繁进行上下文切换时,一个 warp 中的线程使用的缓存数据可能会被另一个 warp 的线程所替换。如果一个 warp 的执行被延迟,其缓存中的数据就有可能在该 warp 重新被调度之前被逐出,特别是当正在处理的数据集合超过了缓存容量时。
GPU SOL
[Warning] Compute is more heavily utilized than Memory: Look at the Compute Workload Analysis report section to see what the compute pipelines are spending their time doing. Also, consider whether any computation is redundant and could be reduced or moved to look-up tables.
Compute Workload Analysis
没有 warning,但是 LSU 利用率最高,看起来仍然在访存上很重
TODO 本栏左右的区别 ALU FMA 与 LSU ALU
Memory Workload Analysis
看图发现 Shared Mem 达到了 55% 的最大带宽,意味着 LSU 访存量大多半是在访问这里

更进一步,Shared Memory 的压力主要来源于 Other,原文指出
As a result of the sweep-style reduction construction considered across the threadblock, there are many iterations of the sweep reduction loop that have one or more entire warps that do not participate. They are predicated off, completely across the warp. These non-participating warps still contribute to shared-memory pressure, and this is reflected in the Other category in the screenshot.
TODO Why “non-participating warps still contribute to shared-memory pressure”?
Page Source
继续看代码,发现 if (id < s) smem[id] += smem[id+s];} 一行是新的 wrap stall 原因,原文给出了一个两阶段的 reduction 算法。当前版本是 1024 维向量相乘结果做 10 次折半规约,新的方法是每 32 个线程做 5 次规约得到 32 个结果,最后再用 32 个线程规约一次得到一个最终结果,节约了 4 次规约
版本四代码
1 | |
达到 5% 理论 fp32 性能峰值
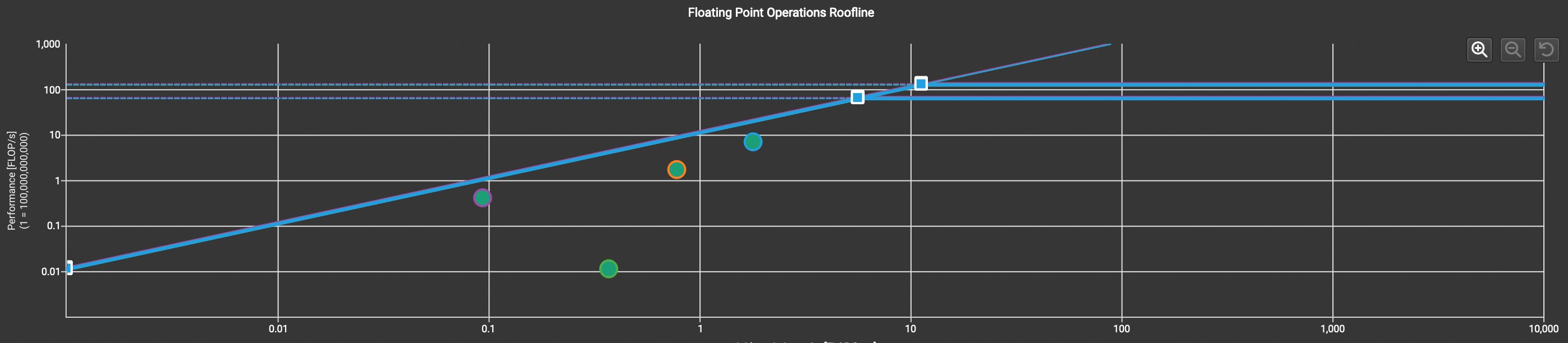
最终版本(0.011824s -> 0.006524s)
这版其实不算我们的优化,主要是重构代码,矩阵乘向量部分转化为矩阵乘矩阵问题,调用 cuBLAS 处理,另一个优势是分两个 kernel 分析更容易定位问题
求平均的 kernel 可以发现已经与 roofline 斜线部分重合,虽然只达到 2% 的计算能力峰值。Memory Workload Analysis 一栏发现,整体利用了 80% 以上的 DRAM 带宽,达到 977.73 GB/s,或者换一种计算方式,我们构造了 4G 的数据,使用 4.40ms(此 kernel 时间)读取加消费完,平均吞吐量是 909GB/s,甚至超过 volta 架构白皮书中声称的 900GB/sec 峰值带宽。
另矩阵乘部分观察到落在 roofline 房顶,达到 84% fp32 理论性能极限
以上这些观察都意味着我们的优化已经接近极限
总结
TODO 关注哪些指标
TODO 补充 https://zhuanlan.zhihu.com/p/464172074
TODO compute peak perf 是怎么计算出来的 https://zhuanlan.zhihu.com/p/231302709
其他
本地 NSight Compute 和服务器上的 NSight Compute 版本一定要一致(包括小版本),否则某些指标不会显示