Bigtable: A Distributed Storage System for Structured Data
pid=72055179
TODO HBase 怎么和 MapReduce / Hadoop 有关的?
BigTable 是一个稀疏、列式、分布式、持久的多维有序映射。它将 GFS 当做 SSTable 与 WAL 用,在 GFS 上层提供宽表的语义,分布式一致使用 Chubby 实现。BigTable 将 KV 进行分片,负责维护每个分片的 memtable,也负责分片的 LB
数据模式
key = (row:string, column:string, time:int64) 类似多列索引
value = string
table = Set[tablet],创建时只对应一个 tablet,随着数据的增长 tablet 会被分裂,每个 tablet 的大小在 100 - 200 MB
column 按 column family 分组,每个 column family 单独压缩,所以 familiy 内应该放相似数据,column family 的数量一般不多,column 的数量则无上限。column key 的名称遵守如下规范:family:qualifier。权限控制最细到 column family 级别。
(其他索引一致时)要避免冲突必须使用不同的 timestamp,支持根据时间或基于保留固定数量的版本数来删除旧数据
存储模式
- 用 kv 的格式存每一列 (row, timestamp, family:qualifier -> value),而不是用行存 (row, family1:qualifier1, family1:qualifier2, family2:qualifier1, … -> value),这也是为什么说 BigTable 是稀疏的
- KV 表用 SSTable 格式存储
- SSTable = List[Block],SSTable 末端存 Block List 的索引 (block index),加载 SSTable 时读到内存,一次 lookup 先在 block index 二分找,然后做一次 IO 读对应的 block(当然也可以选择所有 block 都放到内存)
- Minor Compaction:Memtable 达到 size 阈值后冻结,创建新 memtable,旧的 memtable 转换成 SSTable,写入 GFS。一方面节约 tablet server 内存,另一方面减少恢复时间
- Major Compaction:将所有 SSTable 写为一个 SSTable,一方面减少空间占用,另一方面加速查询
NOTE:注意是每个 tablet 都对应一个 memtable + 多个 sstable
应用场景
Web 索引:row key 为 URL,column family 是 content:, anchor:cnnsi.com, anchor:my.look.ca,分别存储不同时间的网页 html、各个外部链接在不同时间对应的 anchor text
可以被包装成 MR 的输入输出
Guarantees
row key 级别单行读写保证原子性(支持 single-row transaction,可以用来 read-modify-write)
系统设计
- table 根据 row key 做 dynamic partition,每个分片称作 tablet
- 存储:GFS
- 共识:Chubby(确保单 master、存 Root tablet 的位置、tablet server 发现与探活、表结构、ACL),非常类似 ZK
- 系统包含 1 master server + 多个 tablet server,每个 tablet server 有多个 tablet(10 - 1000),每个通常 100 - 200 MB
master 负责将 tablet 动态分配给 tablet server、监控 tablet server 的加入/退出
master 会轮询 tablet server,如果失联,会尝试拿锁,如果能拿到,则确保那个 tablet server 不会再 serve,会删掉文件,然后将属于此 tablet server 的 tablet 重新分配
master 启动时
- 获得 master 锁
- 查 servers directory 获得所有 living server,问这些 server 都保存了哪些 tablet。如果 root tablet 未被分配,分配给一个 server,然后才能读,读完 root tablet 获得第二层的其他 metadata tablet,同样,如果未被分配,先对其分配,之后可以读他们,也就可以读到第三层的普通 tablet 的位置,同样,如果某个 tablet 未被分配,分配给一个 server
Question:为什么要先分配再读?就比如说 root tablet,不能从 Chubby 知道它的信息后,直接读 GFS 吗?
Answer:我的猜测,因为 GFS 是纯粹的存储,master 不会读这么 raw 的数据然后来自己 parse,而是先 assign 一次,复用 assign 的 parse 逻辑,然后可以直接读结构化的数据
Question:tablet assign 到底做了什么?
Answer:文章中有句话the master assigns the tablet by sending a tablet load request to the tablet server,我的理解本质只是一条命令,让 tablet server 去读这个 tablet 在 GFS 中对应的片段(应该也包括 metadata),然后在内存中恢复 metadata、memtable 与 sstable 的索引,之后就可以开始 serve 了
TODO table -> tablet 的映射在哪里管理?
tablet server 启动时在 servers directory 创建一个 Chubby 文件并加锁,拿不到锁的 tablet server 不会 serve,如果 file 都不存在了,它会 kill itself
- 三层索引结构,Root Table (等于 1st METADATA tablet,永不分裂),Other METADATA Table,User Table
client 会缓存 tablet 对应的 tablet server 地址,如果找不到会重新请求上一层索引,最坏的情况,user table 过时、METADATA table 过时、root table 过时,读 chubby 拿 Root Table,读第二层,读第三层,共需要六次 Round Trip。
METADATA Table 也存 Table 的元信息,如创建时间之类的
读写流程
写:直接发往对应的 tablet server,先检查请求合法性,然后检查权限(一般缓存在 Chubby Client 缓存),然后写日志,最后写 memtable
优化
- 会一并访问的数据使用相近的 row key,提供较好的 data locality
- Locality Group,可以看做宽表 (row, col1, col2, col3) 变成 (row, col1) + (row, col2, col3) 两个 locality group,每个对应一个 SSTable(我理解是相当于两套 SSTable),在 col1 通常并不需要与 col2 col3 一并返回时能够提升性能
- 用户可以指定在 locality group 级别是否压缩存储,并不压缩整个 SSTable,而是分块压缩,这样查询的时候可以只解压需要的部分,提升性能
- 两级 Cache,第一级缓存 KV 查询结果(temporal locality),第二级缓存从 GFS 读到的数据块(spatial locality)
- 基于 SSTable 的 KV 如果未命中需要大量 IO,因此提供了 Bloom Filter,如果 Bloom Filter 命中,说明一定不存在,可以直接返回
- 如果每个 tablet 对应一个 WAL,那么由于 tablet 很多,GFS 的并发写入量会高,而 GFS 在这种场景下的写入可能需要重试。因此,BigTable 每个 tablet server 上的所有 tablet 公用一个 WAL,所有 tablet 共用,这样 GFS 的并发写入量就会降低,代价是恢复 tablet 时需要从 mingled WAL 中过滤出属于自己的部分
- 迁移导致的 tablet 重建实际上不需要重建 memtable,在迁移前会做一次 minor compaction,然后停止 serving,然后再对期间产生的 memtable 再做一次 minor compaction。这样迁移后的 tablet server 可以从空的 memtable 开始,而不用从日志中恢复。
- 只有 memtable 有并发读写的问题,BigTable 对于写入采用了 copy-on-write 的策略,这样读写永不阻塞,写入需要先在内存复制
- 分裂后的两个 tablet 仍然共享原有的 SSTable,而不是需要为各自从旧的 SSTable 重新生成
测试
场景
sequential write
sequential read
random read
random reads (mem) 每个 tablet server 数据量限制为 100 MB,使得足够 fit in memory
random writes
scan(scan 的 API 可以减少获取相同数据需要的 RPC 数量)
Workload
R 行数据,每行数据中包含 1000 byte 的随机字符串,取 R 使得平均每个 tablet server 负责 1GB 的数据,R 个 key 被划分为 10N 个区间,被 N 个 client 消费,每次拿一个区间去做读/写操作,取决于 random/sequential,区间内的 key 是排序或随机的
测试结果
scan > mem random read >> seq read = rnd write = seq write >> rnd read
因为 rnd read 每次需要从 GFS 传输 64KB 的 SSTable Block,而实际只用到了 1000 byte。tablet server 读 1200 个 block,等于 75 MB/s,在当时的条件下足够打满 CPU(协议栈、SSTable 解析、BigTable 逻辑),也足够打满网络带宽(?)。这种场景下的应用通常会将 SSTable Block Size 调整为 8KB 来缓解问题。random write 和 sequential write 的 code path 是一致的,所以性能相似。seq read 可以用到预读,所以也快。
从 1 scale 到 500 节点,吞吐量提升数百倍
第一次读时的笔记
文章没有 GFS 好懂,部分内容是推测的
API
- 数据级别:Set(新增或修改)、Delete、CAS、批量接口(非事务)
- Metadata 级别:(增删 column family、table)
- 以及访问权限配置
数据格式
1 | |
举例:
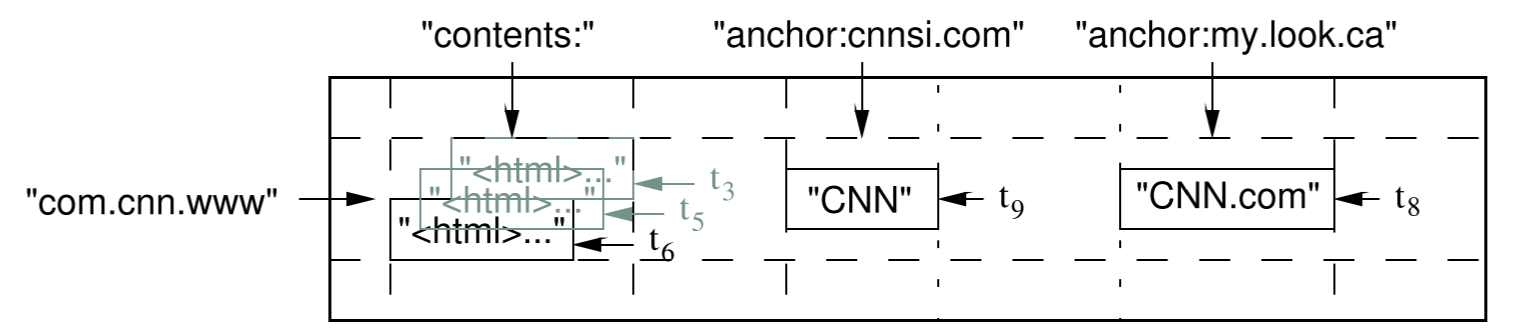
key:类似java包,因为key会排序,这样做有利于相关数据放在一起
名为anchor的column family:cnnsi.com 与 my.look.ca 都引用了 key,引用时使用名称 CNN、CNN.com
contents column family只有一列,但这一列中的这个cell存了三个网页版本
与其他系统的关系
- GFS 是 BigTable 的底层存储
- 有 wrapper 代码使 BigTable 可以作为 MapReduce 作业的输入与/或输出
- 使用 基于 paxos 的 Chubby,它暴露文件 API(类似 ZK),BigTable 用它:
- 选 master
- 存 root tablet
- 存表结构、ACL
- 使用类似 zk ephemeral 节点的功能检测 tablet server 上下线,同时 tablet server 也主动 watch 这个节点,如果 master 将文件删除,意味着这个 tablet server 不再
实现
对应论文 ch5
BigTable 在实现上包括 client lib, master server, tablet server 三类组件
master server 功能:负责管理 tablet 与 tablet server 的映射关系
tablet server 功能:存多个 tablet
client 读写大部分时间直接与 tablet server 交互即可
client data does not move through the master: clients communicate directly with tablet servers for
reads and writes
本节剩余部分参考自[1],对照论文确认过正确性
当master启动的时候,master需要完成以下步骤:
- 在chubby上获取master锁。
- 扫描chubby server directory获取活跃的tabletServer。
- 获取每个活跃的tabletServer上分配的tablet
- 扫描所有的METADATA tablet获取所有的tablet,与3对比,可以获取未分配的tablet,进行分配。在扫描METADATA tablet的过程中,如果发现MEATADATA tablet还没有初始化,就新创建rootTablet和MEATADATA tablet,进行初始化。
tablet在四种情况下会发生变化:创建、删除、合并和分裂。这四种变化中,前三种是由master发起的,最后一种是由chunkServer发起的。tablet的分裂实际上不涉及到数据的移动,只涉及到元数据的更改。chunkServer在对应的METADATA进行元数据的更改和插入,就可以完成分裂操作,然后通知master这个分裂操作。如果这个通知失败了,通过后续的心跳信息,master也很容易知道知道tablet的最新情况。tablet分裂的细节请参考tabletServer一节。
master 负责 tablet 的调度,Bigtable 的数据是存储在GFS上的,数据的调度由GFS负责,master 调度更多是让 memtable 在 tabletServer 间均衡分布。
索引设计
全局的所有数据(跨table)使用三层树状结构维护,类似于 B+ 树,每层都以 tablet 的形式存,数据足够多会导致 tablet 分裂。第一层只有一个 root tablet,维护指向第二层 metadata tablet 的指针列表,永不分裂,root tablet 的位置在 Chubby 中维护;第二层是 metadata tablet,内部每行指向第三层的 tablet;第三层的 tablet 对应某个 table 下的某个 tablet。(我的理解)tablet 的尾部存了 tablet 内部的索引,读到内存,使得 tablet 内部查询仅走一次随机IO(另一个可选项是将整个 tablet 都读到内存)。另,Client 会缓存索引,避免每次都查索引
SSTable 管理
Memtable + WAL + minor compaction (定期 memtable 落盘,我的理解等同于论文中的 redo point)+ 定期 schedule major compaction(合并多个 sstable)
工程优化
来自论文第六节
如果为每个 tablet 维护一个 WAL,由于这些 tablet 可能被调度到不同的 GFS chunk server,多个 tablet 修改产生的 WAL 插入在写入上可能不是顺序写入,(换句话说,单个 tablet server 维护 N 个 tablet,如果全 table 随机写入,这些写入就会转化为 N 个 WAL 文件的顺序写入),论文提出对每个 tablet server 维护一个 WAL(即使维护 N 个 tablet,仍然只写一个 WAL,但是这个 WAL 是所有 tablet server 维护的 tablet 的 WAL 混合起来的,也就是 GFS 的 conrrent + append 场景),但 tablet 恢复过程中需要过滤出此 tablet 写入的 WAL。BigTable 使用的 WAL 格式是 ⟨table, row name, log sequence number⟩,其中包含了 GFS 读取时应用层需要的去重功能
思考
TODO
宽列模式的优势?
选主流程?理论上可以类比利用 zk 实现选主,监听前缀节点即可
Explain the finding process of tablets in BigTable
(来自 KTH DD2221 HW1)
BigTable maintains a METADATA table, in which each row encodes the information (tablet identifier, end row) to find the tablet. A root tablet maintains the location of all tablets in METADATA tablet, and the location of the root tablet is maintained as a file in Chubby.
Clients first need to get the location of root tablet from Chubby, then find the METADATA tablet matching the key that client is reading or writing, then find the row in that METADATA tablet matching the key that client is reading or writing, finally, find the tablet that stores the data from the tablet identifier stored in the row. The client can cache these information so later read/write won’t need these steps.
宽列数据库与列式数据库
BigTable 二者都是
https://db-engines.com/en/article/Wide+Column+Stores
Wide column stores, also called extensible record stores, store data in records with an ability to hold very large numbers of dynamic columns. Since the column names as well as the record keys are not fixed, and since a record can have billions of columns, wide column stores can be seen as two-dimensional key-value stores.
(与 列式存储 的区别)
Wide column stores must not be confused with the column oriented storage in some relational systems. This is an internal concept for improving the performance of an RDBMS for OLAP workloads and stores the data of a table not record after record but column by column.
总结
- 介绍了一个分布式宽列数据库的设计思路
- 将 GFS 封装为 SSTable 使用,同时引入配套需要的 Memtable、WAL、Compaction、聚簇索引(三层,类似 B+ 树,用于根据 key 找 tablet)、表结构/ACL 维护
- Metadata 使用 Chubby 维护
- Memtable 的调度
总结的总结:分布式宽列数据库,存储层使用 GFS,
数据安全已经在 GFS 层解决,本层主要解决引入的 metadata 的安全 和
参考文章
- Bigtable论文阅读总结
TODO 其中还讨论了 Percolator 在 BitTable 单行事务基础上实现的多行事务,值得学习一下