Kafka: a Distributed Messaging System for Log Processing
pid=84327200
本文结合论文与相关文档对 Kafka 进行介绍,文档主要来源于 Apache Kafka,少部分来源于 Confluent Kafka
论文中介绍的是较早期 Kafka 的系统实现,与当前实现有差别,但对于第一次学习此系统仍然是有价值的。(论文部分提出的 Q&A 仍然是基于现有版本的 Kafka 进行讨论)
论文
We have built a novel messaging system for log processing called Kafka [18] that combines the benefits of traditional log aggregators and messaging systems.
概念定义与系统设计
Topic:用于表示一类数据,支持 partition 为分片单位的读写
Broker:存储 partition 的一个节点,一个 Kafka 系统通常有多个 Broker
Partition: 同一个 broker 可以存多个 partition,producer 的 append 与 consumer 的 消费 实际上是以 partition(而不是 topic)为基本单位进行的。每个 partition 物理上对应了多个 segment file。Partition 逻辑上是只 append 的,实际上就是往逻辑上最后的 segment file append。可配置落盘间隔(定时、每多少条消息)。一个 partition 实际上对应多个副本。Partition 是 Kafka 的最小并行单元。
Question:数据是如何分片的呢?按 key(但是数据不一定有 key)还是按数据数量动态调整分片数量?所有分片都承载写请求吗?那读也要与多个 partition leader 同时维护多个连接,按顺序交付给应用?
Answer: 如果写入的数据无 key,那么 round robin 写入,如果有 key,根据 hash(key) 决定发往哪个 parition leader,任何相同 key 的消息总会存在于相同 partition,仅在同一 partition 下的数据保证按顺序读取,parittion 间无此保证;[5所在列表的 第九节]
Answer: partition 数量可以在创建 partition 时指定 [5 的下一节]
Question:partition 是否支持动态调整?
不支持,见此处Record =
timestamp,key: byteArray,value: byteArray,Headers
value = payload
key for enforcing ordering, colocating data, key retentionConsumer Group:消费端也需要 scale out,因此引入 Consumer Group,topic 下的 partition 会被分配给 group 中的各个 consumer,但保证一个 partition 只可能被一个 consumer 消费,这是出减少加锁的考虑。同时也意味着 consumer 数量无法超过 partition 数量
NOTE:这么说由于每个 partition 可以被多个 producer 写入,看来写入是要加锁的
Question: Consumer Group 支持订阅多个 topic 吗?内部的 Consumer 会因为 partition 的重新分配而收到来自不同 topic 的消息吗?
Answer:支持;不会,consumer 只可能收到自己声明订阅的 topic 的消息,见[9]存储格式:仅支持通过 partition 内的逻辑 offset 定位消息
读流程:来自 consumer 的 pull 会携带 offset 与可接受的消息长度,broder 会从内存维护的 offset -> segment file 映射中找到文件并返回数据。Consumer 负责维护准确的当前消费 offset(下文会提到,这一数据会定时同步到 zk),Consumer 读某个 offset 意味着此 offset 前的数据已经全部收到。同一个 Consumer 对单个 Partition 拉取的数据确保有序
TODO Consumer 是如何从多个 parition 拉数据的?维护多个连接吗?写流程:文章没提,但是猜测会根据消息内容路由到某个 parition,然后对 partition 追加写即可
消费者主动从 broker 拉数据(而不是使用推)
支持两种消费模式,第一种:每条数据只到达某一个消费者;第二种:每条数据会到达所有消费者
Question:如果只到达一个消费者,那么在有多个消费者订阅同一个 topic 的情况下,某些消费者的 offset 是跳跃的吗?
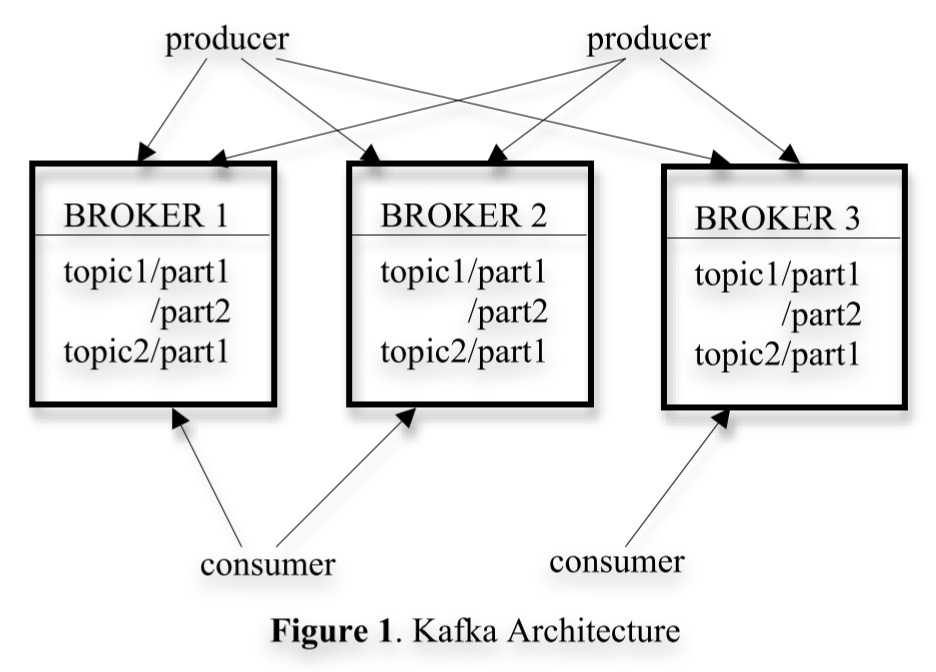
性能优化
- 客户端每次取一个 batch,通常几百K
- 仅依赖磁盘的 page cache,进程挂掉不影响 cache,没有应用层 cache 能减少很多 GC,使得如果使用 VM 语言实现 Kafka 会有更高效率
- 使用 sendFile 系统调用,数据从磁盘 DMA 到内核,再直接到网卡,仅需 一次系统调用 与 两次数据拷贝。对比 read + write 是 两次系统调用 + 四次数据拷贝(DMA * 2 + CPU 拷贝 * 2)
TODO 发包从 内核内存 到 网卡也是 DMA 吗? - 消费进度在消费者维护,使得 broker 无状态,但给持久化的数据的 GC 带来麻烦,因此采用可配置的超时清理策略实现 GC
- 另一个值得一提的优势是,尽管降低了 GC 的精确性,但也使得消费者可以实现“时间回溯”,重新消费已经消费过的数据。考虑场景:消费者定期将消费进度持久化,挂掉后需要从最近的一次 checkpoint 重新开始
分布式
- 论文在 future work 部分指出当前的实现没有考虑数据复制,因此如果节点永久故障会导致数据丢失,将来会考虑引入 同步/异步 的复制
- 每个 partition 同一时间仅允许一个 consumer 消费,不用加锁
- 几乎所有分布式的任务都交给 Zookeeper 完成
- 功能上:
- consumer 与 broker 探活(通过 ephemeral node 实现)
- 维护 parition 如何在订阅 topic 的 consumer 间分配,consumer 或 broker 下线后此关联关系也需要重新分配
- 持久化维护 partition 的消费进度
- 实现上(我的猜测):
- consumer registry 维护存活的 consumer 以及每个 consumer 订阅的 topic
- broker registry 维护存活的 broker 集合、broker 所存储的 parition、topic 信息
- ownership registry 维护 parition 与 consumer 的关联关系(上文提到一个 partition 只能同时被一个 consumer own)
- offset registry 维护每个 parition 的消费进度
- 如果 broker 挂掉,所有其关联的 parition 也自动下掉
- 如果 consumer 挂掉,会导致 consumer registry 与 ownership registry 中的关联 node 下掉
- 每个 consumer 会 watch broker registry 与 consumer registry,因为这二者变化会导致 partition - consumer 关联关系的重新分配
- Consumer 在拉数据的过程中会将消费进度定时同步到 offset registry
- Parition 分配过程:Parition 与 Consumer 排序,将 Parition 平均分配,第 i 个 Consumer 负责消费第 i 段 Parition 集合。一个问题是 watch 得到重新分配这一通知到来的速度是不同的,对于新的分配流程中的节点 A,如果它将自己的 ownership 注册到 ownership registry 失败,那么会删除它目前注册的所有 ownership,等待一段时间后重试(等待冲突节点收到重新分配的通知),论文报告通常在几次重试后可以达到稳定
- 新加入的 Consumer 由于没有存它的进度,可以根据配置从 Partition 的最新或最旧进度开始消费
- 推测实现:将 zk 看做 dict = kv
- consumer registry
dict[/consuemr/consumer1] = ConsumerDetail,由 consumer 创建,ephemeral 节点
- broker registry:
dict[/broker/broker1] = BrokerDetail,由 broker 创建,ephemeral 节点dict[/borker/broker1/parition1] = (paritionDetail, topicDetail),由 broker 创建,ephemeral 节点
- ownership registry:
dict[/ownership/topic1/partition1/ownedBy] = ConsumerDetail,由 consumer 创建,ephemeral 节点
- offset registry:
dict[/offset/topic1/parition1] = offsetDetail,persistent 节点
- 每个 consumer watch
/consumer与/broker目录
- consumer registry
- 功能上:
学习期间思考如何用 zk 的 watch API 完成上述功能,博主参考了[2]中的实验结果
提供何种语义(Exactly-Once, Ordering)
- Kafka 提供 at-least-once,可以推测消费者将数据交给应用层后才异步地发起 offset 更新请求(论文前面也有提到,这个过程是定时的,比异步更差)。在应用层添加额外信息,如递增的消息版本号等,同时在提交给应用层前先对消息持久化,可以实现 exactly-once
- Kafka 保证相同 paritition 对相同 consumer 的消息 deliver 是有序的
- Kafka 对保存的数据做了 CRC,可以减少网络传输中的误码
Future Work
- 目前数据仅在一个节点持久化,如果节点永久 Failure,数据丢失,未来考虑增加 同步/异步 复制策略
- 提供流处理 API
文档
Efficiency(Kafka 为什么快)
文档中提到的点:
- 磁盘:
- 顺序写 + 异步刷盘
- [11]读近期写入的数据直接从 OS buffer 取而不读磁盘,即使需要读磁盘也走零拷贝,数据不进入用户态
- 批量处理:与消费者交互时尽量合并请求,结果上产生了更大的网络报文、更长的顺序读、更多的连续内存占用
- 生产者、Broker、消费者间一致的数据格式:数据从不在 Kafka 做转换,因此能够直接用 sendfile 系统调用避免 context switch 与 数据拷贝到用户态。
如果消费者能够跟上生产者,那么就能够在 pagecache 有效期间完成读取,不走磁盘读,是高效的过程
如果与消费者建立的是 TLS/SSL 连接,对应需要使用 SSL_sendfile 系统调用,但 Kafka 目前还不支持 - 消息压缩:在生产者压缩(文档没说,我的猜测),在消费者解压缩。这是出于网络带宽瓶颈的一项优化
Producer
TODO 找 Leader 的过程合并到下文的 读写流程
直接向 Leader Broder 发送请求。任何 Kafka node 都能够回答某个 topic 的某个 parition 的 leader 是谁(我的猜测,作为代理查下 ZK 即可)。写入支持用户对数据提取 key,根据 key 决定写入哪个分片,这使得消费方能够对读取的值做 locality assumption.
Question:可以指定发往哪个 partition 我理解了,那怎么指定 partition leader,或者 partition 内的节点放在哪个地理位置呢?
TODO
Producer 的发送是异步的,积累到一定消息数量或积累消息达到一定时间后发送,是吞吐量与时延的 trade off
推还是拉(Consumer 与 Leader,Leader 与 follower)
TODO 为什么这么设计
Static Membership
Consumer Eager Rebalancing
Consumer Cooperative Rebalance (Incremental Rebalance)
Consumer Static Group Membership
Exactly-Once & Ordering Guarantee
Kafka 仅当向 client 返回 commit 的数据安全时,为这些数据提供 Exactly-once 语义,换句话说需要将配置设置为 ack=-1, unclean=false, insync 越大越好
接下来分为 Kafka 被写入时 与 Kafka 被消费时 两块进行讨论:
Kafka 被写入时
发布时,0.11 以前的 Kafka 提供 at-least-once,0.11 开始为每个 producer 向 Kafka 发送的消息携带 seq id 实现去重(Kafka 侧变为幂等),从而实现 exactly-once。也是从 0.11 开始,Kafka 支持 producer 以事务语义向多个 topic 发送消息(下文 Transaction 小节会继续介绍)
Question: 上述实现可以对抗重传带来的 at-least-once 问题,但 seq id 在 session 间(或者说 Producer 挂掉后)是如何保证持久性的?
我们先列出不同的 session 可能会导致什么问题,再讨论我们可能该处的解决方案,最后看 Kafka 是如何解决的
- 如果写入方是数据源(如传感器),我们可以有怎样的保证?
对要向 Kafka 写入的数据先写日志(event + seq id),这样在新的 session 我们能够重新发送上一个 session 未收到 ack 的消息,而 Kafka 侧能够对重复的 seq id 做过滤。我们对以下情况无能为力:如果数据源生成的消息在写日志前(或者写日志是非原子的),Kafka 写入方 crash。因为我们已经是消息源,没有任何上游提供跨 session 的保证。 - 如果写入方是 中间节点(如 如一个微服务),对消息做某种转换后写入 Kafka,我们可以有怎样的保证?
- 类似 Kafka,上游可能发生重传,我们需要做幂等处理,收到请求后将 event + seq id 持久化,此时,若本节点无副作用,可以向上游返回 ACK;若本节点有副作用
B, SideEffect = ImpureF(A),需要等待ImpureF计算完成,将 event + seqId + B + SideEffect 持久化后,方可向上游返回 ACK。至此,上游发来的消息确保持久化,确保不受重传影响,接下来的思考不用再考虑上游。
NOTE:无副作用的消息可以在更早的时间点持久化,从而在更早的时间点通知上游 已收到
TODO 如何定义 无副作用?如果 ImpureF 调用了 外部服务,如何讨论? - 当收到某条消息 M 写入 Kafka 的 ack 后,在 M 的持久化信息中标记为 已完成向下游的发送,向上游返回 ACK。仅当确定上游收到这个 ACK 后(比如通过收到上游的下一个消息来证明),可以将 M 持久化占用的空间回收
- 若我们挂掉,上游发来的消息中
消息 + 副作用 已持久化但未确认 Kafka 已收到的部分:可以主动向 Kafka 发起重试
消息 + 无副作用 已持久化但未确认 Kafka 已收到的部分:重新计算后写 Kafaka
消息未来得及持久化,意味着在下个 session 已经丢失:需要依赖上游重新发起请求,本节点才能意识到这一情况
TODO Flink sink 也是这种情况,讨论下它是如何实现的
TODO FlinkKafkaProducer https://github.com/apache/flink/blob/master/flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/FlinkKafkaProducer.java
TODO TwoPhaseCommitSinkFunction
TODO Akka zhihu
TODO END-TO-END ARGUMENTS IN SYSTEM DESIGN https://web.mit.edu/Saltzer/www/publications/endtoend/endtoend.pdf
TODO An Overview of End-to-End Exactly-Once Processing in Apache Flink https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
- 类似 Kafka,上游可能发生重传,我们需要做幂等处理,收到请求后将 event + seq id 持久化,此时,若本节点无副作用,可以向上游返回 ACK;若本节点有副作用
- 是否对于 数据源 与 是中间节点 的情况、处理逻辑有无状态的情况,Producer 实现 guarantee 需要有不同的实现?是否有成熟的方案?
TODO 可以对比下 Flink StateFun - Kafka Idempotent Producer 通过对消息附加版本号实现去重,前文提到的通过持久化应对 session 间丢失状态的方案无法接触这个被封装的逻辑,使得跨 session 的重试在下游 Kafaka 看来则是一条新消息的写入,或者说无法区分消息是重试或是新消息。
这里也提到,Idempotent Producer 仅在 session 内保证 exactly-once
The idempotent producer only guarantees Exactly once semantics at a per partition level and within the lifetime of the producer.
这种情况下的解决方案是在业务层携带 id 对请求进行区分,但仍然会存在相同 id 多次写入 Kafka 的问题,需要在 Kafka 的下游过滤
如果考虑改造 Kafka 的 Idempotent Producer,在前面提到的持久化方案中,应当将 Producer 生成的 id 一并持久化,也可以解决这一问题
NOTE:总结,Kafka Idempotent Producer 未对跨 session 的场景保证 exactly-once,需要通过额外的持久化逻辑实现
TODO Flink 多个 sink 间会需要同步吗?有办法同步吗?
TODO 下面是 Kafka 给出的 exactly-once 解释
https://www.confluent.io/blog/transactions-apache-kafka/
More formally, if a stream processing application consumes message A and produces message B such that B = F(A), then exactly-once processing means that A is considered consumed if and only if B is successfully produced, and vice versa.
Question: 这个 seq id 如何初始化?
TODO https://www.waitingforcode.com/apache-kafka/apache-kafka-idempotent-producer/read#:~:text=What%20if%20my%20producer%20fails%3F
NOTE: 20230111 补充,需要和上述内容合并一下
关于跨 session 的 exactly-once,[15] 给出了一个解决方案,Kafka 能够支持,但需要额外的业务逻辑:
- producer 侧额外维护一个 consumer,重启后 consumer 重新读此 partition 最后成功写入的 消息,来确定哪些消息是 “未 ACK 但成功写入” 的
- consumer 从头开始读显然太慢,可以额外维护一个持久化的字段,每当 producer 发送的消息被 ACK 时,在这个字段记录“这个 offset 已经 成功写入”,恢复时从这个字段的下一个 offset 开始读就行了
Question:目前默认 keyBy 似乎是放到下游的流处理系统来做,如果在 kafka 做,会导致一个 producer 写多个 partition,那如何保证同一个 producer 的消息能够被按顺序消费呢?
https://youtu.be/twgbAL_EaQw?t=1900
Answer:同 producer 对需要有序的消息需要加上相同的 key
ref: https://stackoverflow.com/a/46128819/8454039
So, if you have more than one partition in the topic, you’ll need to set the same partition key for messages that you require to appear in order.
同时单个 producer 发送的消息若要确保有序,还需要将 max.in.flight.requests.per.connection 设为 1,否则可能引发 request 级别的重排序
ref: https://stackoverflow.com/a/53490942/8454039
To avoid this problem you should always use the same key for the messages that you need the order.
Question:决定发往哪个 partitioner 函数是什么,在哪里计算?
我理解应当是在 producer 计算,否则在 broker 还需要额外的转发。具体使用的算法是 murmur2
实现
见下图,图源指出这也是 非幂等 Producer 可能导致顺序错乱的一个 case(猜测不在 replication 时将 batch 看做原子的原因是因为性能)
图中向 ISR leader 发一个 batch,但 replication 不是以一个 batch 为单位进行的,这会存在如下图的问题,leader 挂掉,replication 不完整,新 leader 接受了完整的重传数据,破坏了消息顺序 与 exactly-once。打开 enable.idempotence=true 选项后会在消息上附带 (producer id, seq num) 来唯一标记一条消息,broder 侧则为每个 prducer id 维护 last seen seq num,从而解决这一问题
![图源[6 course 8]](https://raw.githubusercontent.com/vicety/Images/master/images20221129221350.png)
现在的 Kafka 默认是 exactly-once 吗?
acks 默认为 all (-1)
enable.idempotence 默认为 true
类似的,max.in.flight.requests.per.connection 默认为 5retries 默认为 0
TODO 为什么默认为 5
https://www.waitingforcode.com/apache-kafka/apache-kafka-idempotent-producer/read
Note that enabling idempotence requires max.in.flight.requests.per.connection to be less than or equal to 5 (with message ordering preserved for any allowable value), retries to be greater than 0, and acks must be ‘all’.
所以 producer 侧就我看到的配置而言是 at-most-once 的,配置 retries 为 MAX_VALUE 后是 exactly-once 的(网上看到一些说法默认是 at-least-once)
Kafka 被消费时
拉数据、处理数据、存进度对应着 at-least-once
拉数据、存进度、处理数据对应着 at-most-once
如果消息幂等,那么可以直接采用 at-least-once 的方案,消费方只需要偶尔持久化一下消费进度,使得恢复不至于太慢即可。否则若要实现 exactly-once,重点在于如何实现同时更新 A.消费方消费进度 与 B.消费方因本次消费产生的副作用。方案一是对AB做二阶段提交;方案二,原子地把AB写入存储
TODO Kafka 是不是可以通过 txn 实现?
TODO consumer 挂了会发生什么,待总结
https://stackoverflow.com/questions/49916055/kafka-behaviour-if-consumer-fail
TODO consumer 挂掉重启后如何获知上次的消费进度
https://kafka.apache.org/22/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html
The committed position is the last offset that has been stored securely. Should the process fail and restart, this is the offset that the consumer will recover to.
https://developer.confluent.io/learn-kafka/architecture/consumer-group-protocol/
When a consumer group instance is restarted, it will send an OffsetFetchRequest to the group coordinator to retrieve the last committed offset for its assigned partition. Once it has the offset, it will resume the consumption from that point. If this consumer instance is starting for the very first time and there is no saved offset position for this consumer group, then the auto.offset.reset configuration will determine whether it begins consuming from the earliest offset or the latest.
TODO 关于如何 commit 消费进度
TODO 可以参考这里 https://www.cnblogs.com/FG123/p/10091599.html,大致就是默认 auto-commit,也可以手动,但没法保证原子地写入消息处理结果与 commit 进度,除非你的消息和 commit 进度是按 txn 写入 kafka 的
https://kafka.apache.org/22/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html
(似乎文档里也有这句话)
The consumer application need not use Kafka’s built-in offset storage, it can store offsets in a store of its own choosing. The primary use case for this is allowing the application to store both the offset and the results of the consumption in the same system in a way that both the results and offsets are stored atomically. This is not always possible, but when it is it will make the consumption fully atomic and give “exactly once” semantics that are stronger than the default “at-least once” semantics you get with Kafka’s offset commit functionality.
TODO 问题,那么往 topic 写入的消费进度是如何支持读取的呢
Kafka store the offset commits in a topic, when consumer commit the offset, kafka publish an commit offset message to an “commit-log” topic and keep an in-memory structure that mapped group/topic/partition to the latest offset for fast retrieval.
大意是在内存维护了一份,可以直接拿到(而不用消费那个 topic,这个 topic 估计也不是用来消费的),看下面这个例子
NOTE: 虽然只是一个 proposal
All replicas will keep the in-memory lookup structure for offsets. This could just be a simple hashmap. This will contain only committed offsets to ensure we never need to undo updates.
如果消费者是 kafka 的 topic,那么可以利用 Transactional Producer,Transaction 除了会写 target topic,还会在一个专门的 topic 记录消费 offset,也就是解决了上面说的同时更新的问题。注意使用此特性需要设置 isolation_level 为 read_committed
TODO 这个原理和二阶段提交是否一样?
Question:partition 数量是否支持运行时变更?consumer group 是否支持运行时扩缩容?
TODO
Question:尝试与 TCP 的 exactly-once 进行对比?
- TCP 的 ACK 需要携带 ack num 作为参数,因为它支持多个请求 on-the-fly,需要辨别是谁的 ACK
- TCP exactly-once 的一个前提是节点/进程不出现 failure,或者说仅在 session 内保证这一 property。实现上仅维护当前处理进度即可,类比上面的 at-most-once,处理数据 部分等价于向上层协议/应用 deliver 报文,由于不考虑 failure,实际上等价于 exactly-once
Transaction
考虑 Application 收到转账请求,往 topic A 写加钱,topic B 写扣钱,我们希望这个写入有 transaction 的性质
如何开启:processing.guarantee=exactly_once_v2, Consumer 侧开启 isolation.level=read_committed
[10 ch4.6] Also beginning with 0.11.0.0, the producer supports the ability to send messages to multiple topic partitions using transaction-like semantics: i.e. either all messages are successfully written or none of them are. The main use case for this is exactly-once processing between Kafka topics (described
below).
再举一个实际一些的例子,Flink 单个 sink 向 Kafka 的 exactly-once 写入在前文已经讨论过,对于多个 sink 的情况(无论它们写入一个或多个 Kafka Topic),问题在于
1 | |
Transaction 实现
TODO 感觉是个很大的话题,还需要看下[6]以外的其他材料
TODO 可以参考这篇 https://www.confluent.io/blog/transactions-apache-kafka/
- 找到 txn coordinator(使用与 consumer coordinator 相同的策略决定,下文用 tc 代替),这个 broker 会维护一个 internal topic
- 请求 tc 分配一个 txn id
Ordering Guarantee
省流:相同 producer instance 产生的 相同 key 的数据确保有序被消费
Events with a specific key will always land in a specific partition in the order they are sent, and consumers will always read them from that specific partition in that exact order.
[6 course 8] This is actually an end-to-end per-key ordering guarantee.
数据复制
论文发表时还没有数据复制相关的方案,这块内容在文档[3]中做了详细描述,此外也强烈推荐[7]
Kafka 为每个 partition 选主,通常 partition 比 broder 数量多很多,parition 的 leader 在 broder 间均匀分布(类似于 GFS 的 chunk 与 chunk server 方案)
Kafka 引入了 ISR 机制:ISR (in-sync replicas) 是一个节点集合,集合内的节点走同步复制(Confluent Kafka 的同步复制时通过 follower 向 leader 拉实现的,Apache 没看),其余节点走异步复制。选主仅从 ISR 集合选(由于是同步复制,任意 ISR 都可以成为 Leader)(有选项可以从任意节点选,下面会介绍),当同步复制使得消息扩散到所有 ISR 的时刻开始,只要 ISR 任意节点存活,消息可以视为 commit
Motivation:认为类似 Raft 的 majority vote 复制太重了,只适合 metadata 的维护(etcd、zk、consul)。具体来说,支持至多 2 节点宕机需要 5 节点。而对于上述方案,能够使用 f+1 replica 承受 f 个副本的宕机。但这是以可用性换来的一致性(ISR 不可用时选择整个系统不可用,而不是允许往非 ISR 节点写入,牺牲一致性来换取此场景下的可用性),并且实现它需要设置一些参数:
- ack=1/0/-1,分别代表:
- partition leader 收到消息后向生产者返回 ack
- partition leader 不向生产者返回 ack
- partition leader 以及该 partition 的所有 ISR 收到消息后向生产者返回 ack
显然 ack 不为 -1 的情况下 ISR 同步复制也就无从谈起,数据是不安全的。ack=0 时丢包就会导致数据丢失,ack=1 时 leader 挂掉,若有其他的 ISR 节点之后被选为 leader 可能会导致数据丢失,ack=-1 时

unclean.leader.election.enable(topic 级别配置):是否允许非 ISR 集合中的节点成为 leader。如果 ISR 结合为空,节点保持不可用状态直到任何 ISR 节点复活
由于 ISR 走同步复制,且尽管 Kafka 将数据通过系统调用推到操作系统后不强制刷盘,只要有任何 ISR 存活,数据就能确保不丢。这一选项也是 availability 与 durability 的权衡,考虑持久性应当关闭
Tips: 关于通过系统调用写入但未刷盘的数据的一致性问题
https://cs61.seas.harvard.edu/site/2019/Storage/
Every access to the disk is made through the operating system kernel, through system calls, and an important part of the kernel’s job is to ensure that the buffer cache is kept coherent—that write system calls made by one application are visible to system calls made by other applications as soon as those writes are made.
min.insync.replicas(topic 级别配置):仅当 sizeof ISR 大于此配置值时,系统接受写入请求。
考虑两个极端:
- (min.insync 的默认值)
ack=-1 unclean=false min.insync.replicas=1:- 写入时:只要 leader 还在写入就不会阻塞
- leader 挂掉后,如果当时正好 ISR 集合只有 leader 本身,将导致集群不可用
ack=-1 unclean=false min.insync.replicas=N:- 写入时:任意节点挂掉都会使 sizeof ISR 小于 min.insync,导致写入阻塞
- leader 挂掉后,可以忍受至多 N-1 个节点挂掉,假设从这唯一的存活节点恢复后,尽管写入仍然阻塞,但读取不走广播,读不阻塞
Tips: 只要任何 ISR 节点存活,读就不阻塞
[4] As long as one partition is up and considered an ISR, the topic will be available for reads
总结:较小的 min.insync 意味着较好的写入可用性,更差的读取可用性,反之亦然
This setting only takes effect if the producer uses acks=all and guarantees that the message will be acknowledged by at least this many in-sync
replicas.
Leader Epoch 机制
先介绍几个概念:HW 高水位线,类似于 Raft 的 commit index,LEO Last End Offset,本地最大日志 index + 1
前面介绍了,尽管有 ISR 存活的情况下,重选的 Leader 确保消息不丢,但 HW 的推进总是比 LEO 的推进要慢的,换句话说,重选的 Leader 可能不知道自己拥有的某些数据是否是 committed 的。问题在于,[1]中指出以前的策略会按照 HW 做日志截断,这显然是不安全的。
NOTE: [1]中还介绍了一个 unclean 策略打开情况下发生的一个更坏的情况:Leader A 同步消息 m 给 B,B ack 后挂了,由于数据不刷盘,数据也丢了,但 B 还在 ISR 集合,B 成为 Leader 开始接受数据,导致 m 所在 index 的数据被覆盖。
Kafka 引入了 Leader Epoch request 来代替 HW 用于日志裁剪
Each replica keeps a vector of [LeaderEpoch => StartOffset] to mark when leaders changed throughout the lineage of its log. This vector then replaces the high watermark when followers need to truncate data (and will be stored in a file for each replica).
具体流程如下[2]
- Leader 的消息中携带 Leader Epoch
- 每次当选 Leader,Leader Epoch++,同时记录此 LE 对应的起始日志 offset,刷盘
- 当 Replica 成为 follower,向 Leader 发送 Leader Epoch request,消息体中包含 follower 所知的最大 LE 值,Leader 响应中返回此 LE 的下一 LE(如果有)对应的起始日志 offset(如果没有下一 LE,返回此 LE 的最大 offset),follower 如果日志超出此 offset,做裁剪,此后继续向 Leader fetch 日志,如果日志的 LE 提升了,那么需要将 LE、LE 对应的日志 offset 刷盘
总结一下:重启成为 follower 时会向当前 Leader 拉当前 LE 的最大 offset 来决定是否需要裁剪
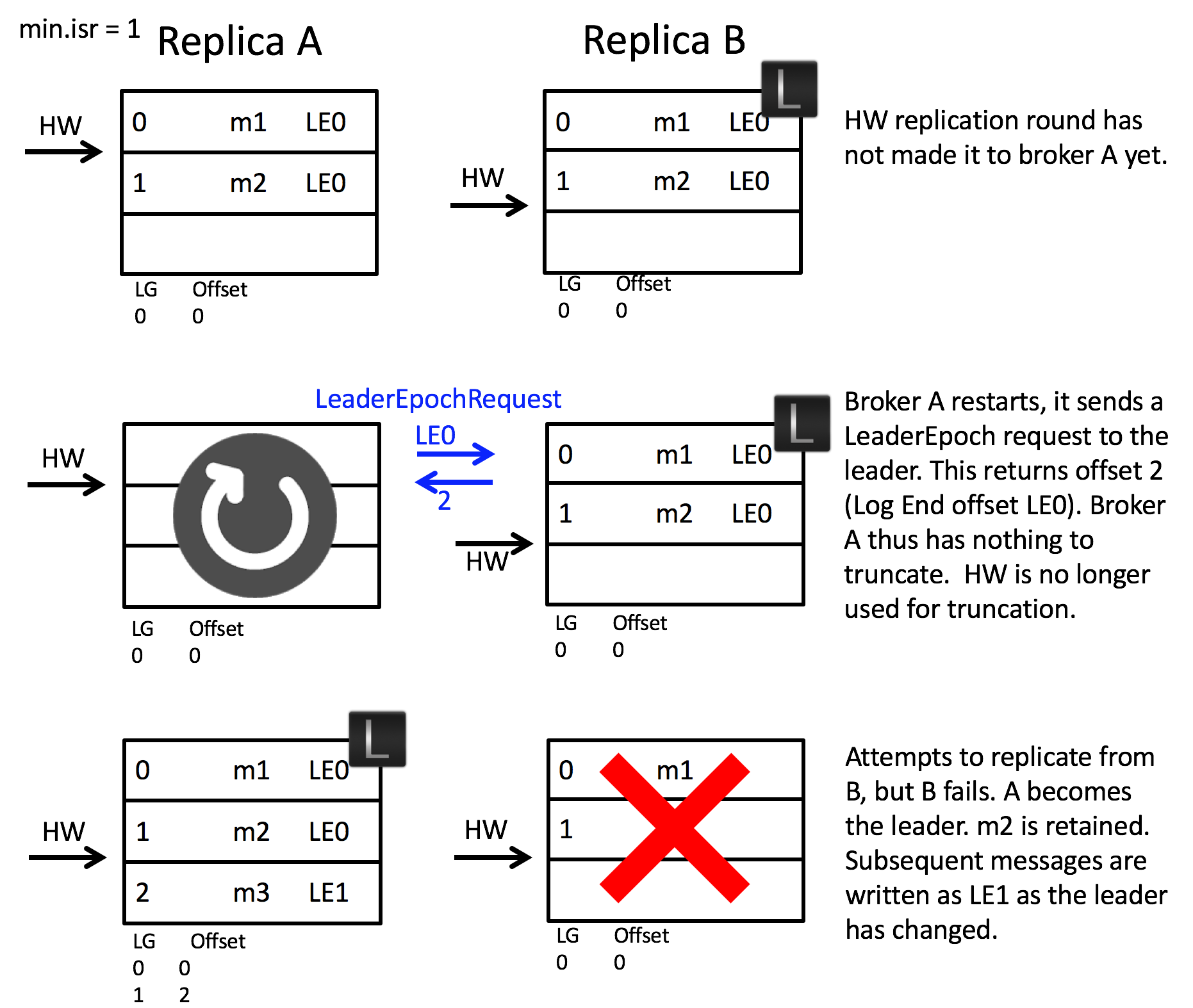
Question:如果 ISR 只剩下 follower 自己了呢?
在 ISR 集合确保所有 committed 数据 要么已经持久化,要么在 OS buffer
那么 follower 会当选 leader,而 leader 是不需要走 Leader Epoch request 的,多出的未 commit 数据不会被裁剪
TODO Question:follower 如何知道当前 Leader?猜测是在 ZK 维护
本节参考
- 为什么Kafka需要Leader Epoch?
- KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation
其他优化
Partition Leader Balancing[7]:Leader 的负载更高,因此希望均匀分布 leader。Partition 副本集合中会指定一个 preferred replica,指定策略会时 preferred replica 均匀分布,选主时,当选条件满足的情况下优先选 preferred replica
问题
Question:ISR 数量是手动配的还是通过某种 Failure Detector 动态维护的?
Answer: 是动态的
Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted in the cluster metadata
whenever it changes.
Question:被踢出 ISR 的指标是什么?
replica.lag.time.max.ms,最多容忍这么长时间进度未跟上 master,默认是 10000- ISR 挂掉(zk 后端通过 ephemeral node 实现)
Question:这个 check 是怎么实现的?
TODO 可能要看源码了,让我设计的话,master 同步复制时携带进度,每次跟上进度时重置定时器,到达时间后主动向 zk 汇报落后信息(如果与 zk 的连接不同,由于使用 ephemeral node,仍然能检测到)
Question:ISR 机制这么好,为什么 Raft 不用?
Answer: 因为 ISR 集合的维护还需要额外的服务支持,在 Kafka 中是 ZK 或 KRaft。也就是说你没法用依赖 Raft 的设计实现 Raft。
文档[3]中提到:Quorum 系统适合维护配置,但需要 2f + 1 节点来保证 f 节点宕机情况下的强一致性 + 可用性
doing every write five times, with 5x the disk space requirements and 1/5th the throughput, is not very practical for large volume data problems. This is likely why quorum algorithms more commonly appear for shared cluster configuration such as ZooKeeper but are less common for primary data storage.
(我的理解)ISR 机制是一种 控制与数据分离的设计,控制数据(ISR 集合)使用 Quorum 系统(ZK)实现,而业务数据则可以根据配置获得不同的 写可用性、节点容错数量(min.insync)。举个例子,min.insync=6, replication factor=7,使得容错为 5,而 Raft 在相同的 replication factor 容错为 3(当然代价是写可用性下降)
Question:考虑 7 节点挂 6 个,剩下的属于 ISR,背后的 Raft 肯定已经不可用了,难道不影响数据写入吗?
TODO 有 dedicated 节点用来部署 KRaft 的方案,应该还是基于这个方案思考的。x 个数据面节点,最多容忍 x-1 节点宕机,不重合的 2y+1 个控制面节点(即 KRaft)容忍最多 y 节点宕机,上一个问题中提到的优势只是对于数据面节点而言的
Question:ISR 是如何动态维护的?ISR 的维护有延迟会有问题吗?
ISR 的维护不需要强一致
server 侧
如果未同步的 follower 持续存在于 ISR,会影响可用性,但由于其会阻塞 HW 的前进,任何未同步到所有 ISR 的日志都不会向 client 返回 ACK(即尚未向 client 做出任何关于这条消息的承诺),因此不会对一致性造成影响
如果已同步的 follower 暂时未被加入 ISR,同样会影响可用性,但是是反映在 Leader 挂掉后有多少 ISR 可选这一层面上的
client 侧
如果向非 ISR 节点发送请求,且它也认为自己是 ISR
Question:如果消息同步复制到 ISR 的过程中,在任何 ISR 将其从 OS buffer 刷盘前 ISR 挂掉(比如 sizeof ISR = 1 的情况),是否意味着数据丢失?
[3]
With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.Note that Kafka’s guarantee with respect to data loss is predicated on at least one replica remaining in sync. If all the nodes replicating a partition die, this guarantee no longer holds.
[12]是的,但当配置较大的 min ISR 时,这个概率会很小,只要在 ISR 中任何一台机器完成 flush 前没有出现 ISR 内所有机器挂掉,就不会有问题
TODO os buffer flush 一般要多久呢?
(os flush 耗时是否比同步复制的延迟要短?是的话这个概率会进一步缩小)
Question: 如何保证 Producer 不会将数据写入过时 leader 并得到 ACK?如何保证 Producer 获知的 Leader 即使是过时的也不会有问题?比如说,Leader 挂,选出新 Leader,旧 Leader 复活,怎么保证 Producer 无法写入旧 Leader,或写入旧 Leader 一定无法成功?
TODO 我的猜测,leader 更换会从原有的 ISR 中选一个,假设为 A,选完后(已经在 Raft 集群持久化),若原有 leader 复活,client 继续往它写入,可以确保的是 A 一定能够拒绝来自原 leader 的复制,且 A 一定在原 leader 的 metadata 中,若原 leader 更新 metadata,也能够发现自己已经不再是 leader(用类似 epoch 的机制)
https://qr.ae/pr27Xu
The producer sends a Metadata request with a list of topics to one of the brokers in the broker-list you supplied when configuring the producer.
The broker responds with a list of partitions in those topics and the leader for each partition. The producer caches this information and knows where to redirect its produce messages.
https://stackoverflow.com/a/64832726/8454039
Kafka clients are receiving the necessary meta information from the cluster automatically on each request when reading from or writing to a topic in case of a leadership change.
Each individual broker contains all meta information for the entire cluster, meaning also having the knowledge on the partition leader of other brokers.
Now, if one of your broker goes down and the leadership of a topic partition switches, your producer will get notified about it through that mechanism.
可能相关
https://stackoverflow.com/questions/63451849/does-kafka-broker-always-check-if-its-the-leader-while-responding-to-read-write
So if metadeta which producer fetches every 5 mins is the only validation in kafka for which broker is the leader. Then kafka producer should be able to produce the message at a non-leader broker, if a leader change happens in those 5 mins. Is this understanding correct?
https://kafka.apache.org/08/documentation.html
retry.backoff.ms
Before each retry, the producer refreshes the metadata of relevant topics to see if a new leader has been elected.
TODO 无关问题,有空移走
Question:为什么计算机存储结构不是单层的,而是需要 cache memory disk (even distributed fs) 这么多层?
https://cs61.seas.harvard.edu/site/2019/Storage/
We cannot build a storage system from a single type of digital technology that is simultaneously big, fast, and cheap. So instead, our goal is to create a storage system made up of layers of different storage technologies that gives the appearance of being big and fast. It will cost a bit more than a big and slow storage system, but it will also cost a lot less than a big and fast one.
Confluent Kafka Courses
Consumer Group
本节引用:https://developer.confluent.io/learn-kafka/architecture/consumer-group-protocol/
省流:__consumer_offsets topic 中 group id 关联的 partition leader 被称为 Group Coordinator,Consumer Group 中第一个向 Group Coordinator 发送 JoinGroupRequest 的会被指定为 Group Leader,后者负责根据相应策略在本地完成 parition-consumer 的分配,并将此分配同步到 Group Coordinator,其余 consumer 也会从 Group Coordinator 同步获知这个分配
请求流程:
- consumer 向任意节点发送
FindCoordinator(group.id)请求,返回 consumer group 对应的 Group Coordinator。
注:hash(group.id) mod partition_num(__consumer_offsets topic)决定此 consumer group 的 metadata (我理解主要也就是 offset)向__consumer_offsets的哪个 partition 写入,Group Coordinator 就是这个 partition 的 leader - consumer 向 Group Coordinator 发送
JoinGroupRequest请求,GC 会将第一个请求来源的 consumer 指定为 group leader。这一请求的 response 总是包含 group 内的 member id,对于 leader 会额外返回 all members and the subscription info - Group leader 在本地根据策略分配 partition,并通过
SyncGroupRequest将分配传给 GC,其他 consumer 也会发送这一相同请求,但用于获知自己的分配
此外,OffsetFetchRequest 请求用于获得已提交消费进度,如果没有相关信息,那么会根据 auto.offset.reset 确定初始的消费位置
相关段落
The broker that hosts the leader replica for that partition will take on the role of group coordinator for the new consumer group.
The coordinator will choose one consumer, usually the first one to send the JoinGroup request, as the group leader. The coordinator will return a memberId to each consumer, but it will also return a list of all members and the subscription info to the group leader. The reason for this is so that the group leader can do the actual partition assignment using a configurable partition assignment strategy.
消费期间,consumer 可以通过 CommitOffsetRequest 向 Kafka 持久化消费进度
通过 Map<TopicPartition, OffsetAndMetadata> committed(final Set<TopicPartition> partitions) 可以获得 partition 的已提交 offset
通过 long position(TopicPartition partition) 可以获得 partition 的消费进度
(position 与 committed 区别参考 https://stackoverflow.com/a/47548737/8454039)
Question:如何检测 Consumer 宕机?检测到后会发生什么?
Consumer 与 Group Coordinator 会维护心跳
[14] An instance fails to send a heartbeat to the coordinator before the timeout and is removed from the group
(便于理解的基础版本,[14]中指出了它的问题)GC 检测到后收回所有原先的分配,所有 consumer 重新走 JoinGroupRequest 与 SyncGroupRequest 的流程
Question:如何检测 Broker 宕机?检测到后会发生什么?
这里指维护数据的 topic 而非维护 metadata 的 topic
TODO
分配策略
Round Robin 平均分配
Sticky Partition 同上,但 rebalance 时尽量保证原有分配不变
Rebalance
触发条件
- consumer 心跳超时
- group 加入 consumer
- topic partition 变动
- wildcard 订阅,topic 加入
- group startup
The rebalance process begins with the coordinator notifying the consumer instances that a rebalance has begun. It does this by piggybacking on the HeartbeatResponse or the OffsetFetchResponse.
TODO
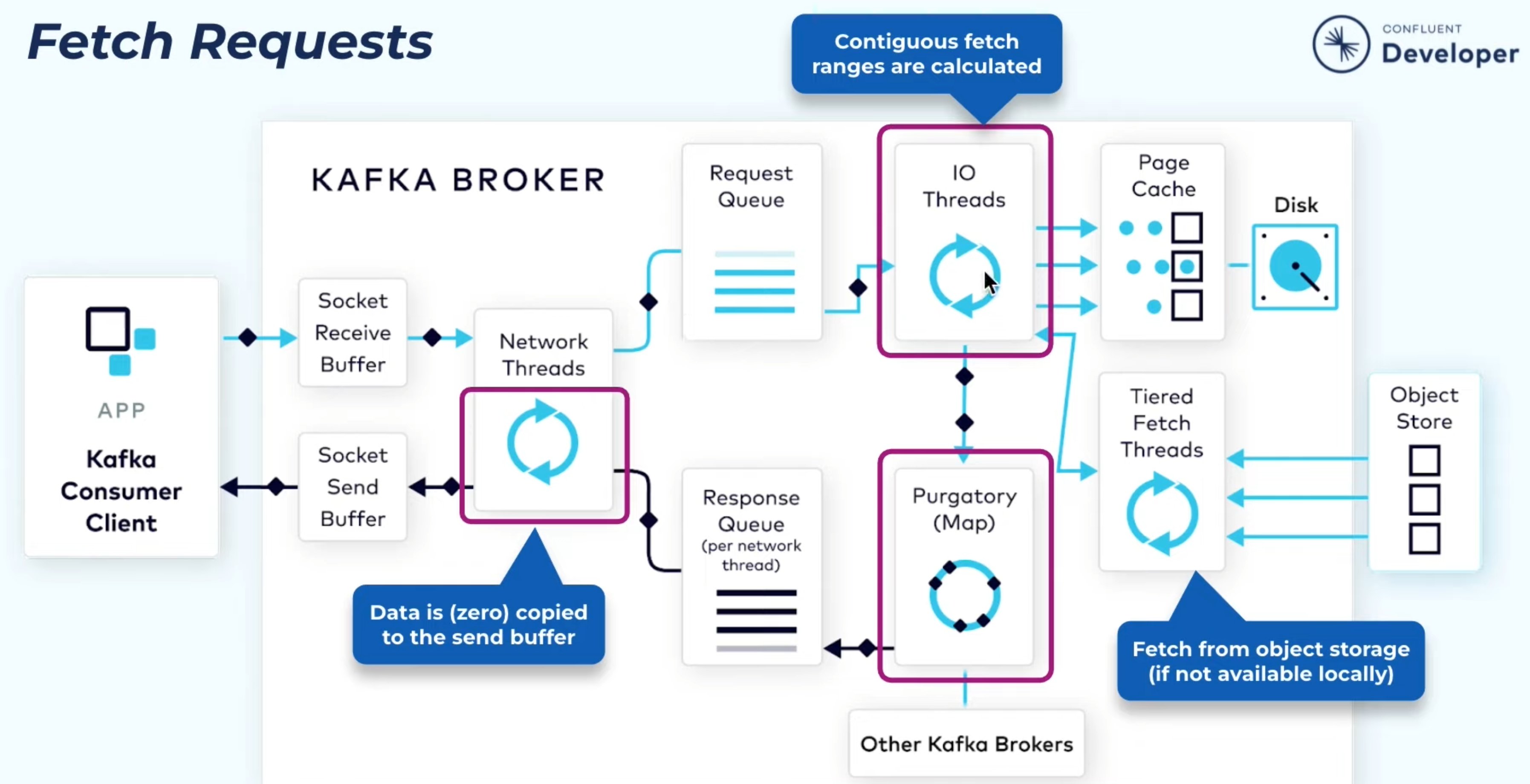
读写流程
本节参考 Inside the Apache Kafka Broker
TODO 补充参考中缺少的 client 找 broker 的过程
TODO 读不能从 follower 读吗?按 index 读相比于读状态机应当是有优化空间的
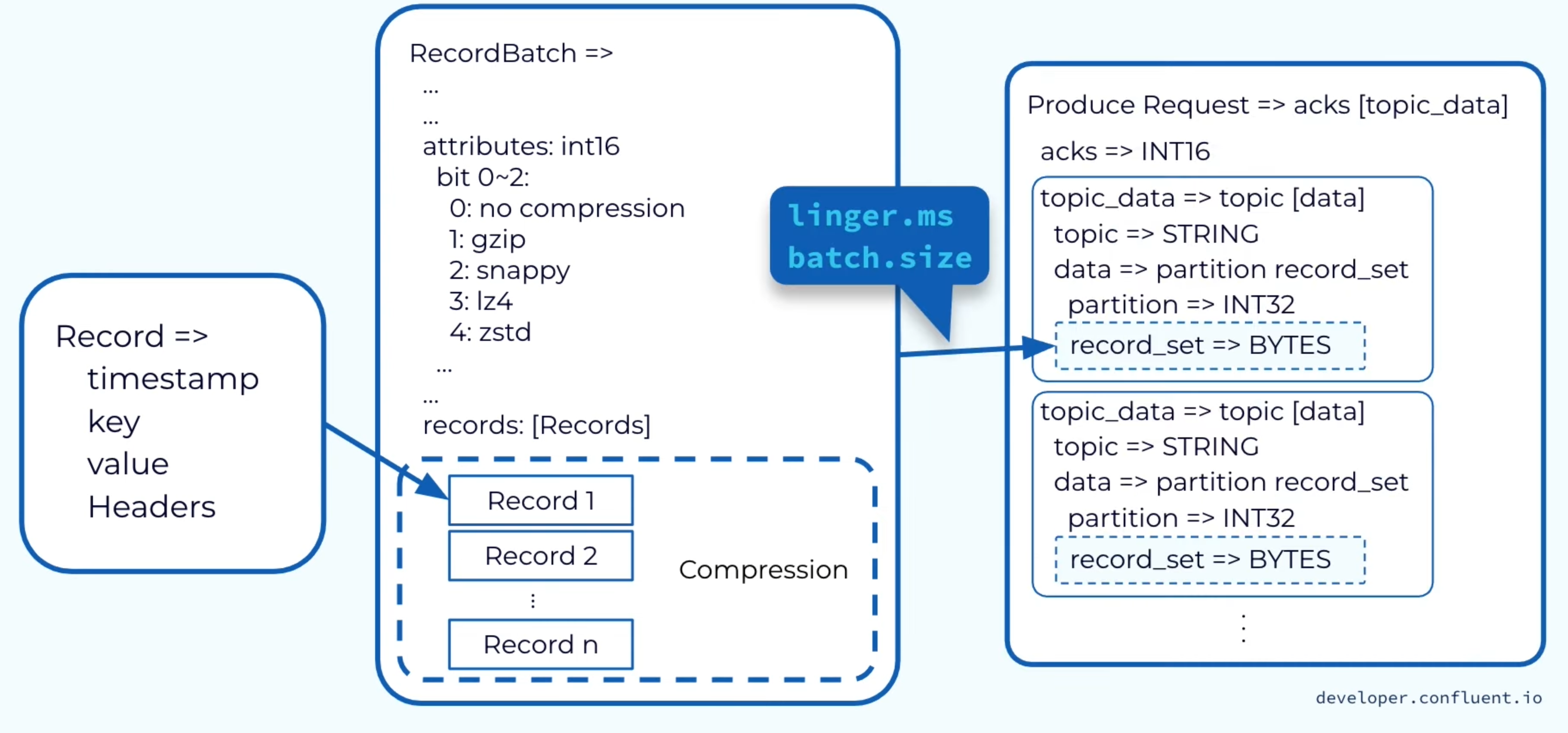
client 发送消息过程:
linger.msbatch.size任一作为触发批量发送的条件- 可配置消息压缩类型
- (猜测)图中 ack 消息中的 record_set 指的是 offset
关于 ack 消息格式可参考这个类,其暴露了获得 offset、partition 的方法
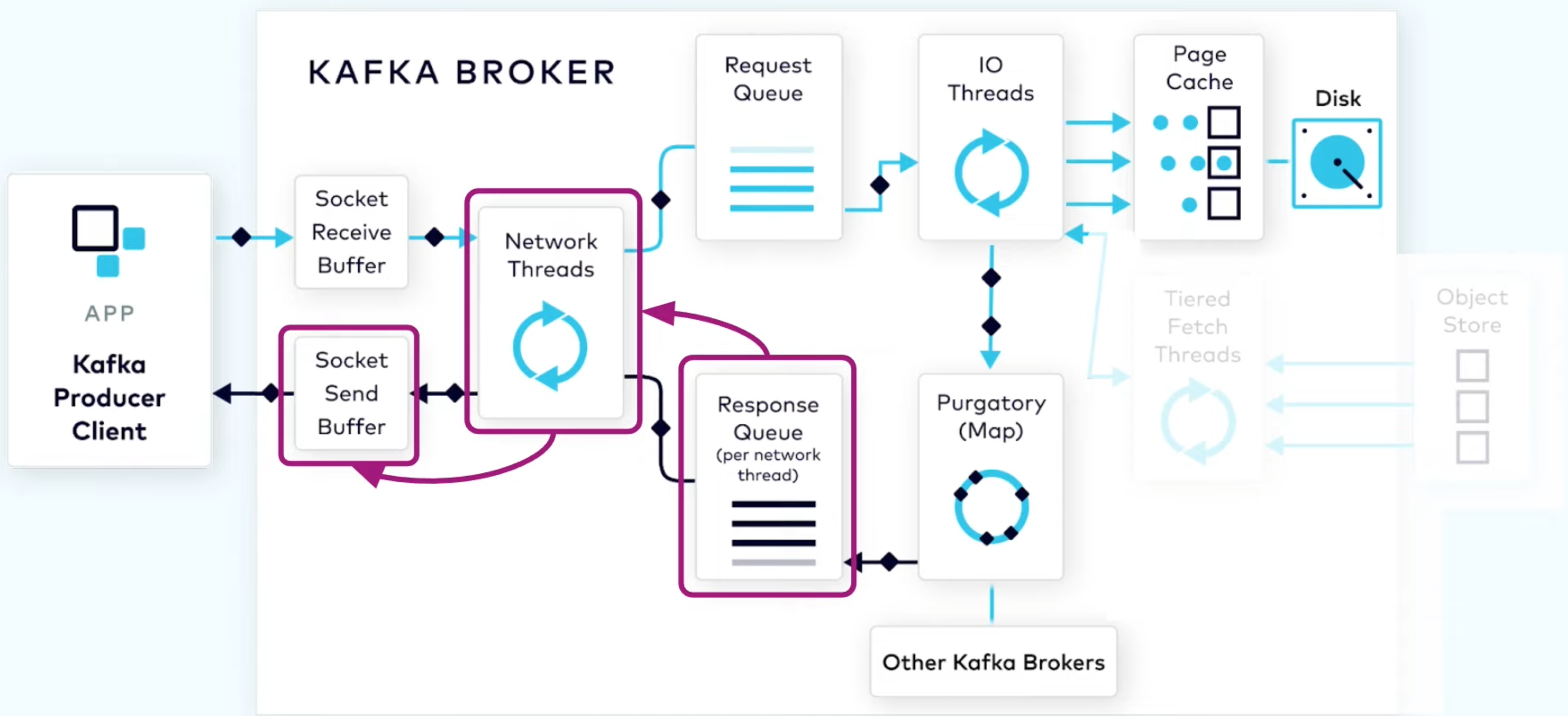
Broker 处理 producer 请求流程:
- Network thread 的收发与client 绑定(连接复用)
- Request Queue 是全局的,Response Queue 是 per thread 的
- (猜测)用的是 TCP,用于保证 in flight 消息间的顺序
- 磁盘维护 segment,存真正的数据,以及一个 index,维护 offset 与 byte range 的对应关系。
- IO thread 阻塞到系统调用结束,后续的同步复制不再阻塞 IO thread,而是使用 Purgatory (一个 map)维护这一 pending replication,同步复制完成后,根据此 map 找到 pending replication 的相关信息,构造 response,根据 connection 推入对应 thread 的队列,等待 thread 消费
Broker 处理 consumer 请求流程与写请求类似,值得一提的点:
- 类似于 producer 以 batch 推消息,Broker 发给 consumer 也有类似的参数
fetch.min.bytes(default 1) 与fetch.max.wait.ms(default 500) - 较新的数据可能还在 page cache,较老的数据也会走 sendfile 零拷贝,两条路径都是效率优化过的
- (未验证)
consumer.poll(long)指定的是客户端 timeout,注意与上面的fetch.max.wait.ms区分,参考
Apache Kafka Control Plain – KRaft
本质上是一个 Raft 协议,存储部分使用一个 Kafka Topic 实现,此 Topic 仅含一个 Partition,Partition Leader 即 Raft Leader。与数据面不同的是,复制流程(猜测)是半同步复制,且写入时强制刷盘,由于已经没有背后的 consensus 服务维护 ISR,选举流程依然是 Raft 的选举流程,参考资料[8]中也提到了 Snapshot 的实现。
Question:为什么用 KRaft 代替 ZooKeeper?
- 由运维两个系统变为运维一个系统,降低运维压力
- 针对 Kafka 的 强一致 metadata store 优化。如支持 dedicated 节点作为 Raft 节点,更快的故障恢复时间等
调优
Producer 调优:linger miliseconds & batch size(flush 前的 最大等待时间、最大消息数量,默认 0 16KB)
调优这两个参数做的一些实验 https://developer.confluent.io/learn-kafka/architecture/producer-hands-on/
TODO 补充下方文章中的内容
如何学习kafka? - 腾讯技术工程的回答 - 知乎
https://www.zhihu.com/question/456093354/answer/2754225999
总结
- Producer 如何 scale?Consumer 如何 scale?
- Producer 侧允许 Partition 级别多 Producer 并发写入[13],由 partition leader (即某个 broker) 作为 sequencer 决定消息顺序,因此 Partition 的 scale out 相对简单
(但 consumer 侧不支持,这使得单 consumer 总能在 partition 上有序消费) - 对 Consumer 与 Broker 的 watch 使得 Parition 与 Consumer 的关联关系能够随着 Consumer 的加入/挂掉、Broker 的加入/挂掉 实现自动调整,从而实现 scale out
- Producer 侧允许 Partition 级别多 Producer 并发写入[13],由 partition leader (即某个 broker) 作为 sequencer 决定消息顺序,因此 Partition 的 scale out 相对简单
- Kafka 自身如何 scale?
增加节点即可,partition 会分散在不同的 broker 上 - Kafka 提供哪些 Guarantee,为什么需要这样它们?是如何提供的?
- Exactly-Once: Idempotent Producer +(跨 session producer 的额外逻辑)+ ISR Replication + Consumer 原子写入消费进度与副作用
- 同 Partition 保证写入与消费顺序相同
TODO Transaction
- 为什么 producer 推,consumer 拉
TODO - 消费进度的维护
TODO - 数据复制:ISR 内同步复制,其余异步复制
- 运行效率(Kafka 为什么快),关键词:Producer Batch、写 OS Buffer 能够利用缓存,利用不上的情况下零拷贝、报文压缩
新特性
KIP-405: Kafka Tiered Storage
https://cwiki.apache.org/confluence/display/KAFKA/KIP-405%3A+Kafka+Tiered+Storage
[Accessed Feb, 2023]
希望能将 Kafka 作为长期存储源,当前通常需要设置一个相对短的 retention time(通常 3 天),需要额外将数据导入到持久存储(如 HDFS)来实现长期存储能力。同时,当前 Kafka 的存储能力依赖于增加更多的 broker,这意味着使用更多的 CPU、内存,意味着存储资源的扩展与计算资源的扩展耦合,希望避免这样的问题
Failover 或 新节点加入 后需要将数据复制到新节点,将 Kafka 的部分存储交给 Tiered Storage 使得可以为 Kafka 配置更少的 rentention time,即减少了由 Kafka Broker 管理的数据,有利于改善 recovery / rebalance time。
On-premise Kafka 的部署通常在 broker 节点 attach 数十 TB 的本地存储,这样的配置在云上很贵或者不存在,类似第二点,降低由 Kafka Broker 本地管理的数据量能够缓解这一问题
顺便提一下 Flink Table Store,which 是一个 流读流写、支持 OLAP 的存储,同样也能够避免从 Kafka 额外同步到 OLAP DFS 的逻辑,但相对于 Tiered Storage 强调了支持 OLAP 的能力。
TODO
TODO:broker 挂后,如何影响 producer?如何影响 consumer?
TODO partition 数量可以一开始指定,之后可变吗?变化涉及的数据迁移有什么优化吗?
TODO 读写流程 https://yangyangmm.cn/2021/10/24/Kafka%E7%9A%84%E8%AF%BB%E5%86%99%E6%B5%81%E7%A8%8B/
Kafka 的一些高级特性介绍
https://medium.zenika.com/some-cool-features-you-may-not-know-about-apache-kafka-953a601f5af5
https://developer.confluent.io/learn-kafka/architecture/geo-replication/
Multi-Region Cluster 国内多机房级别,注意 consensus 层需要引入第三个机房,否则仍然无法抵抗一个机房的故障
也提供了异步复制、从 Follower 读的方案,可以确定异步复制是可能丢数据的,Follower 读不确定
TODO 看下 Kafka 的设计文档中的:
Geo-Replication
多租户
监控
参考文章
- 论文 Kafka: a Distributed Messaging System for Log Processing
- zookeeper(四)watcher
- 4.7 Replication
- Kafka Topic Configuration: Minimum In-Sync Replicas
- COURSE: APACHE KAFKA® 101: Partitioning
- COURSE: APACHE KAFKA® INTERNAL ARCHITECTURE: The Fundamentals
- Data Plane: Replication Protocol
- The Apache Kafka Control Plane
- Using same consumer group for different kafka topics
- Kafka 文档 第四章 Design
- How Kafka Is so Performant If It Writes to Disk?
- Can a message loss occur in Kafka even if producer gets acknowledgement for it?
- Can multiple kafka producers produce the same topic with the same partition at the same time?
- COURSE: APACHE KAFKA® INTERNAL ARCHITECTURE: Consumer Group Protocol
- Kafka - Exactly once semantics with Matthias J. Sax - What happens when the producer crashes