pid=99230581
本文主要基于源码介绍 select / poll / epoll 技术(实际上并没有 poll )
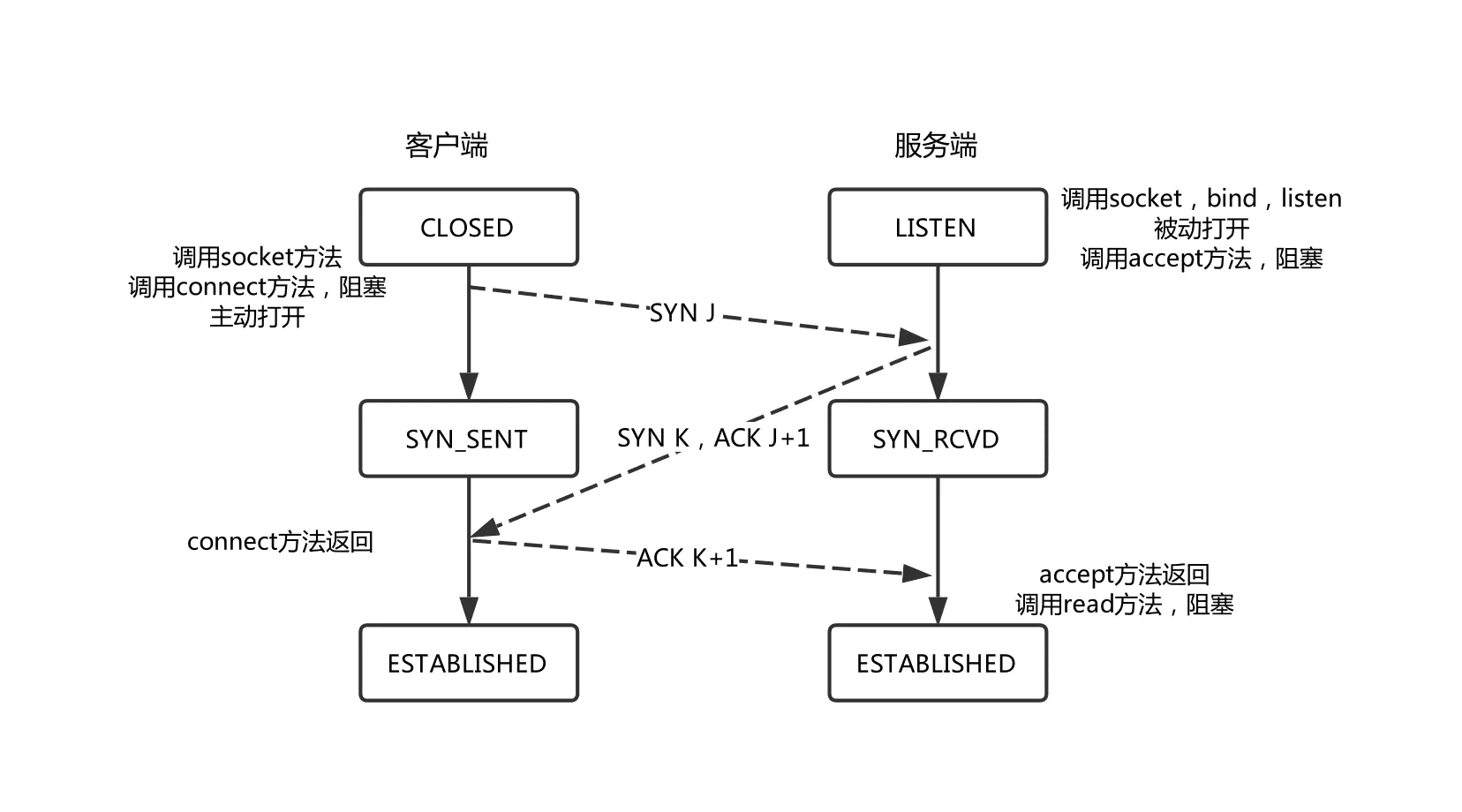
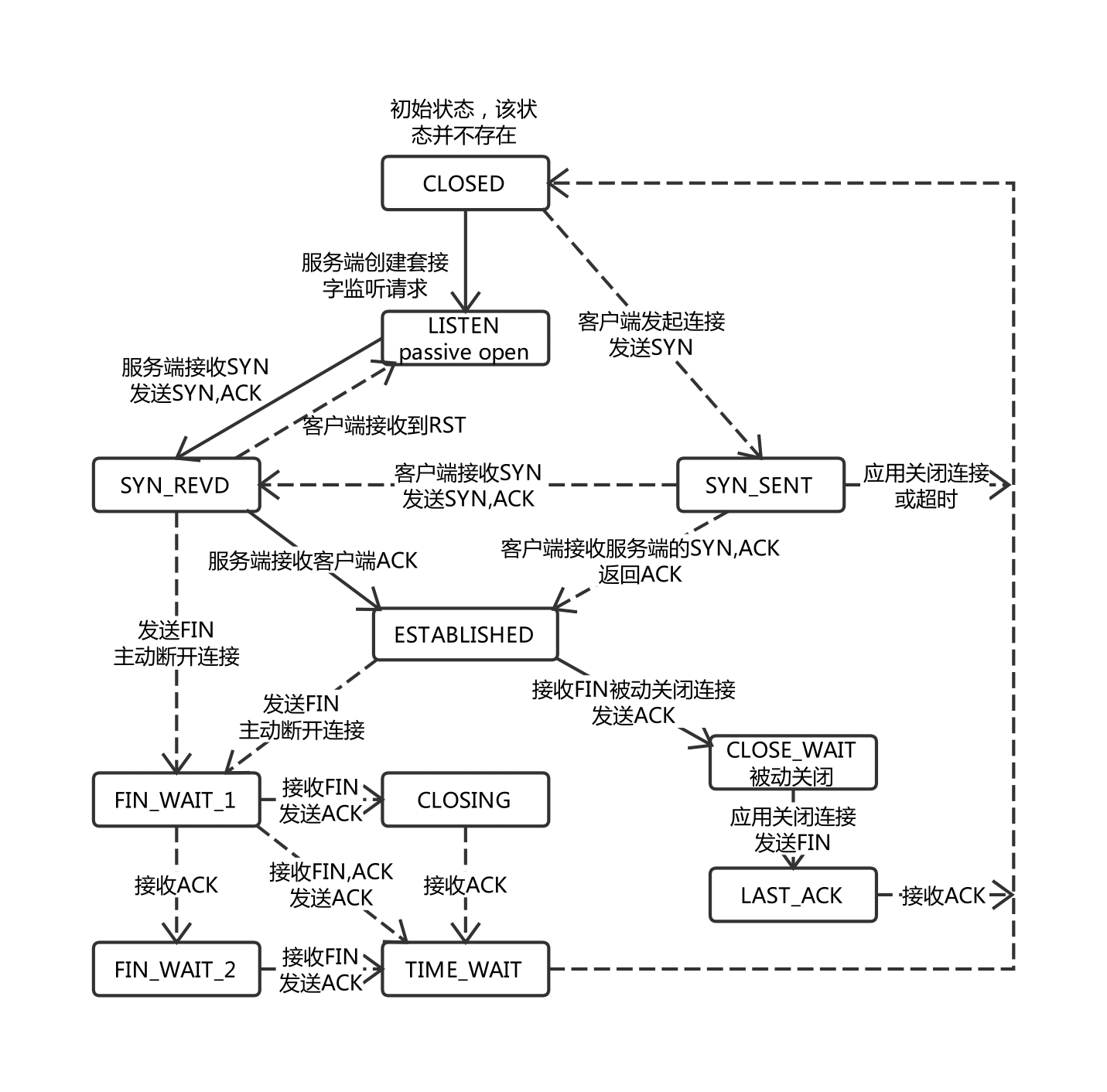
回顾socket编程 推荐阅读[1]
listen 时创建半连接、全连接队列,半连接队列对应SYN_RCVD状态的连接,全连接队列对应 ESTABLISHED 状态的队列,accept 从全连接队列消费
半连接队列满的场景:SYN Flood 攻击,[2]中做实验模拟了此场景
全连接队列满的场景:accept 的消费速度跟不上第三次握手收到后新连接加入全连接队列的速度
TODO
为什么一般不多线程读写单个 socket,怎么理解https://www.zhihu.com/question/56899596/answer/150926723 https://blog.csdn.net/weixin_34357887/article/details/93720482
参考文章(回顾socket编程)
Linux Socket编程(不限Linux) 从一次 Connection Reset 说起,TCP 半连接队列与全连接队列
select select基本使用 select 的使用例子可以参考[5],为避免每次都打开网页,摘录一部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 fd_set rset; 0 , &rset); 4 , &rset); 5 , &rset); if (select(5 +1 , &rset, NULL , NULL , NULL ) > 0 ) if (FD_ISSET(0 , &rset)) if (FD_ISSET(4 , &rset)) if (FD_ISSET(5 , &rset))
源码阅读 select主要逻辑 2.6.39 内核源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 SYSCALL_DEFINE5(select, int , n, fd_set __user *, inp, fd_set __user *, outp,exp , struct timeval __user *, tvp) struct timespec end_time , *to =NULL ;exp , to);long stack_fds[SELECT_STACK_ALLOC/sizeof (long )]; 2 *size;3 *size;4 *size;5 *size;if ((ret = get_fd_set(n, inp, fds.in)) ||exp , fds.ex)))if (ufdset)return copy_from_user(fdset, ufdset, nr) ? -EFAULT : 0 ; goto out;struct poll_wqueues table ;0UL ; 0 ;for (;;)unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp ;exp = fds->ex;for (i = 0 ; i < n; ++rinp, ++routp, ++rexp)exp ++;if (all_bits == 0 ) {continue ;for (j = 0 ; j < __NFDBITS; ++j, ++i, bit <<= 1 )int fput_needed;if (i >= n)break ;if (!(bit & all_bits))continue ;if ((mask & POLLIN_SET) && (in & bit))NULL ; NULL ;if (retval || timed_out || signal_pending(current)) break ;if (set_fd_set(n, inp, fds.res_in) ||exp , fds.res_ex))return ret;1 , ret);
注意:select中没有清理bitmap的操作,返回的bitmap再次传入前要 FD_ZERO 一下
file侧逻辑 以网络编程常见的socket场景为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 struct socket {const struct proto_ops *ops ;const struct proto_ops inet_dgram_ops =static const struct file_operations socket_file_ops = {struct poll_wqueues table;for ;;for fdpoll_wait (filp, wait_address, p) ; if (p && wait_address) struct poll_table_entry *entry = poll_get_entry(pwq);
select callback分析 从do_select出发一路追踪callback的执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 struct poll_wqueues table ;struct socket *sock ;return sock->ops->poll(file, sock, wait);struct file *file, struct socket *sock, poll_table *wait)return datagram_poll(struct file *file, struct socket *sock, poll_table *wait) struct sock *sk = sock->sk;return &rcu_dereference_raw (sk->sk_wq) ->wait; if (p && wait_address)struct file *filp, wait_queue_head_t *wait_address, poll_table *p)struct poll_wqueues *pwq =struct poll_wqueues, pt); struct poll_table_entry *entry =struct poll_table_page *table =if (p->inline_index < N_INLINE_POLL_ENTRIES)return p->inline_entries + p->inline_index++;wait_queue_t *wait, unsigned mode, int sync, void *key)struct poll_table_entry entry =struct poll_table_entry, wait);struct poll_wqueues *pwq =0 ;if (sk->sk_err || !skb_queue_empty(&sk->sk_error_queue))if (sk->sk_shutdown & RCV_SHUTDOWN)if (sk->sk_shutdown == SHUTDOWN_MASK)if (!skb_queue_empty(&sk->sk_receive_queue))if (sock_writeable(sk))return mask;
select callback调用时机 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 wait_queue_head_t *q, unsigned int mode, int nr_exclusive, void *key)typedef struct __wait_queue_head wait_queue_head_t ;struct __wait_queue_head {spinlock_t lock;struct list_head task_list ;typedef struct __wait_queue wait_queue_t ;struct __wait_queue {unsigned int flags;void *private;wait_queue_func_t func;struct list_head task_list ;
如何实现一个支持select的设备 参考了[3],其中还有代码实现,实现起来并不止下面这些,但下面的是核心
定义一个等待队列头 wait_queue_head_t ,用于收留等待队列任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct socket {struct sock *sk ;struct sock {struct socket_wq __rcu *sk_wq ;struct socket_wq {wait_queue_head_t wait;typedef struct __wait_queue_head wait_queue_head_t ;struct __wait_queue_head {spinlock_t lock;struct list_head task_list ;
实现 fd 的接口 file_operations (中的一部分?),可以确定的是 poll 函数是一定需要实现的,通常命名为 xxx_poll()
xxx_poll() 函数中
需要对 poll_wait 进行调用,将 select 传来的 poll_table* wait 与 第一步中提到的 wait_queue_head_t 传入
该函数的返回值 mask 需要返回当前 fd 可读状态之类的信息,比如 EPOLLIN / EPOLL / EPOLLERR 等,这个返回值在 do_select() 函数中会去判断处理
条件满足的时候(比如有数据可读了),通过 wake_up_interruptible 系列API唤醒任务,传入第一步中提到的 wait_queue_head_t
Select缺陷 经典八股
fd 两次拷贝
FD_SETSIZE=1024,而文档中提到当 fd 值超过 1024 时,FD_SET 系列宏的行为是 undefined 的
https://pubs.opengroup.org/onlinepubs/7908799/xsh/select.html
https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/posix_types.h#L27
1 2 3 4 5 #define __FD_SETSIZE 1024 typedef struct {unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof (long ))];typedef __kernel_fd_set fd_set;
通常直接在栈上申请 fd_set,按照上面的类型定义,会有1024的问题,而下方链接的博主尝试在堆上分配时可以超过1024的https://blog.csdn.net/dog250/article/details/105896693
只知道有事情发生了,仍然需要O(n)遍历,使用 FD_ISSET 去检查是否是这个 FD 有事件
Select是ET还是LT? 根据源码分析中socket实现的poll可知,poll返回的是接受队列是否为空,所以至少对于select常见的socket编程场景下是LT的
总结 其实看上面怎么自己实现一个支持select的设备就够了,select本质就是对监听的每个fd尝试poll,若无消息(暂不可读)则向其注册一个wake函数,其中写了当前进程,若全部file无消息则调用进程睡眠。file内部需要在有变化时主动调用 wake_up_interruptible 之类的函数,并将注册有 wake函数的容器传入,实现解除select的阻塞
参考文章(select)
如果这篇文章说不清epoll的本质,那就过来掐死我吧! (2) 图解Linux网络包接收过程 【原创】Linux select/poll机制原理分析 TODO 没看完 但是强推 Linux网络 - 数据包的接收过程
Linux网络编程——I/O复用之select详解
TODO 如果多个进程阻塞使用相同的fdset去调用select?
poll TODO 可以简单介绍一下
epoll epoll基本使用 可运行的例子见[7],下面摘录网上的另一个例子,出处找不到了……https://github.com/abbshr/C10K-web-server/blob/master/event-driven-model/epoll-server.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 struct epoll_event ev , event [MAX_EVENT ];0 );sizeof (on) );const struct sockaddr *)&server_addr, sizeof (server_addr));200 );0 );int wait_count;for (;;)-1 );for (int i = 0 ; i < wait_count; i++)uint32_t events = event[i].events;if ( events & EPOLLERR || events & EPOLLHUP || (! events & EPOLLIN))else if (listenfd == event[i].data.fd)for (;;) int accp_fd = accept(listenfd, &in_addr, &in_addr_len);sizeof (in_addr),sizeof (host_buf) / sizeof (host_buf[0 ]),sizeof (port_buf) / sizeof (port_buf[0 ]),printf ("New connection: host = %s, port = %s\n" , host_buf, port_buf);else int done = 0 ;for (;;)sizeof (buf) / sizeof (buf[0 ]));if (-1 == result_len)if (EAGAIN != errno) "Read data" );1 ;break ;else if (! result_len)1 ;break ;if (done) printf ("Closed connection\n" );return 0 ;
epoll源码阅读
结构定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 struct eventpoll {wait_queue_head_t wq;wait_queue_head_t poll_wait;struct list_head rdllist ;struct rb_root rbr ;struct user_struct *user ;struct rb_root {struct rb_node *rb_node ;struct epitem {struct rb_node rbn ;struct list_head rdllink ;struct epoll_filefd ffd ;struct file *file ;int fd;int nwait;struct list_head pwqlist ;struct eventpoll *ep ;struct epoll_event event ;struct epoll_event {struct epoll_event {uint32_t events; epoll_data_t data;
初始化 第一次关注 fs_initcall,介绍可以参考 https://cloud.tencent.com/developer/article/1554770
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fs_initcall(eventpoll_init);struct sysinfo si ;unsigned long totalhigh; unsigned long totalram; unsigned long freeram; unsigned int mem_unit; 25 ) << PAGE_SHIFT) /
epoll_create 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 SYSCALL_DEFINE1(epoll_create, int , size)int , flags)struct eventpoll *ep =NULL ;sizeof (*ep), GFP_KERNEL); "[eventpoll]" , &eventpoll_fops, ep,return error; static const struct file_operations eventpoll_fops =
epoll_ctl 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 SYSCALL_DEFINE4(epoll_ctl, int , epfd, int , op, int , fd,struct epoll_event __user *, event)struct epoll_event epds ;sizeof (struct epoll_event))if (file == tfile || !is_file_epoll(file))goto error_tgt_fput; struct rb_node *rbp ;for (rbp = ep->rbr.rb_node; rbp; )struct epitem, rbn); if (kcmp > 0 )else if (kcmp < 0 )else break ;switch (op)case EPOLL_CTL_ADD:if (!epi) case EPOLL_CTL_DEL:if (epi)case EPOLL_CTL_MOD:if (epi)
追踪一下 ep_insert
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 ep_insert(struct eventpoll *ep, struct epoll_event *event, struct file *tfile, int fd)struct epitem *epi ;struct ep_pqueue epq ;typedef struct poll_table_struct {__poll_t _key;struct epitem *epi ;if (unlikely(user_watches >= max_user_watches))return -ENOSPC;0 ;if (p && wait_address)struct file *file, wait_queue_head_t *whead, poll_table *pt)struct epitem *epi =return container_of(p, struct ep_pqueue, pt)->epi; struct eppoll_entry *pwq ;if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL)))wait_queue_t *wait, unsigned mode, int sync, void *key) struct epitem *epi =struct eppoll_entry, wait)->base; struct eventpoll *ep =if (key && !((unsigned long ) key & epi->event.events))goto out_unlock;if (!ep_is_linked(&epi->rdllink))if (waitqueue_active(&ep->wq)) wait_queue_head_t *q, unsigned int mode)1 , 0 , NULL );if (waitqueue_active(&ep->poll_wait))if (pwake)return maskif ((revents & event->events) && !ep_is_linked(&epi->rdllink))if (waitqueue_active(&ep->wq))if (waitqueue_active(&ep->poll_wait))if (pwake)NULL , wq, (void *) (long ) this_cpu);void *priv, void *cookie, int call_nests)wait_queue_head_t *) cookie, POLLIN, 1 + call_nests);0 , key); return 0 ;
1 2 3 4 5 6 7 8 9 void __wake_up(wait_queue_head_t *q, unsigned int mode,int nr_exclusive, void *key)
epoll_wait 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 SYSCALL_DEFINE4(epoll_wait, int , epfd, struct epoll_event __user *, events,int , maxevents, int , timeout)sizeof (struct epoll_event))if (!is_file_epoll(file))return errorstatic int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,int maxevents, long timeout)int res = 0 , eavail, timed_out = 0 ; wait_queue_t wait;if (timeout > 0 )else if (timeout == 0 ) if (!ep_events_available(ep)) 0 ;for (;;)if (ep_events_available(ep) || timed_out)break ;if (signal_pending(current))break ;if (!expires) schedule () ; return -EINTR;if (!res && eavail &&struct ep_send_events_data esed ;return ep_scan_ready_list(ep, ep_send_events_proc, &esed);struct ep_send_events_data *esed = priv;for (eventcnt = 0 , uevent = esed->events; !list_empty(head) && eventcnt < esed->maxevents;)struct epitem, rdllink); NULL ) &if (revents)if (!(epi->event.events & EPOLLET)) return eventcnt;return error;goto fetch_events;return res;
总结(epoll) TODO 看一下[2]的源码说明
与 select 类似的是都用到了 Linux 的等待队列机制,有代码复用,所以读起来轻松不少
流程分析 TODO pollwake 的深入分析请见 http://gityuan.com/2018/12/02/linux-wait-queue/
context 为 poll 时:向 socket 的等待队列添加包装后的函数指针
context为 sk_data_ready -> wake_up_interruptible_sync_poll -> __wake_up_sync_key ->__wake_up_common -> list_for_each_entry_safe -> curr->func这个curr中是包含了select/epoll_wait调用时记录的当前进程的,因此可以知道要唤醒谁 (epoll 的不完全正确,但可以这么理解)
epoll_ctl分析 从 EPOLL_CTL_ADD 开始分析:
epi 对应一个加入的 fd,会加入红黑树(与 ready list),其中包含一个 qproc,随后调用 file 的 poll 时,file 的 poll 应当会调用poll_wait,并将poll_table传入(通过container_of可以找到包裹poll_table的epi),qproc 调用时,会申请一个 eppoll_entry 对象,它的主要作用是包装callback ep_poll_callback,加入file的等待队列(ctl_add时加入,ctl_del时删除)。file在状态变化时应主动调用callback,这个callback做三件事:
过滤用户不关心的状态变化,避免走到下面导致唤醒
将 epi 添加到 readylist(如果没有已经添加的话)
如果ep的等待队列不为空(有进程阻塞在当前 epfd 的 epoll_wait),遍历它们 (wait_queue_t),在其中能找到阻塞进程的 task_struct,唤醒它们
epoll_wait分析
如果 ep 的 ready list 为空,那么自己将要阻塞,申请一个 wait_queue_t 对象,填入当前进程的task_struct,添加到ep的等待队列,不断调用schedule让出CPU,每次被唤醒(或被调度)时检查ready list是否为空。
ready list不为空的状态下,遍历ready list调用poll ,过滤取得的 mask(与运算),将事件消息(哪个 fd 触发、是什么事件类型)拷贝回用户态传入的 buffer。如果是LT,有用户关心事件的fd会放回ready list,下次epoll_wait时会略过步骤1,重新poll,因此实现了LT。ET则不会放回ready list,需要file主动汇报状态触发install的callback才能重新使ready list非空,因此实现了ET 。
与select的比较
select 每次调用全量拷贝了用户感兴趣的fd到内核状态,而epoll是增量的
select 使用bitmap维护感兴趣的fd,O1插入删除、On遍历(这里不讨论用户态与内核态的拷贝),而epoll平衡了插入删除与遍历,均为红黑树复杂度
select 每次调用与唤醒时需要On poll一遍,epoll 在 epoll_ctl 需要 poll 一次,后续 epoll_wait 阻塞前不 poll,唤醒后 poll 一次,注意 epoll 只 poll 有事件的 fd
配一张图便于理解
ET与LT的区别 LT不会清理 wait_list,下次调用 epoll_wait 时会重新对 file 进行 poll,若无关心的事件才会移出队列,而 wait_list 不会保留在队列中,意味着这是监听的 fd 下次主动汇报状态之前(以 socket 为例,等价于有新数据)仅有的一次通知机会。或者先CTL DEL后ADD也可以重新触发 poll
(我的理解)一个必须使用ET的场景:如果消息处理与 epoll_wait 的调用不在同一个线程,那么为了 epoll_wait 返回后再次调用时不立即再次返回(如果其他线程还未来得及从 buffer 中拿走数据),需要使用 ET
为什么有人说ET更快 我的理解,LT每次调用 epoll_wait 如果使用阻塞 fd 只能读一次来避免阻塞,但如果使用非阻塞fd倒是和ET没什么区别
[5] 在 eventloop 类型(包括各类 fiber / coroutine)的程序中, 处理逻辑和 epoll_wait 都在一个线程, ET相比LT没有太大的差别. 反而由于LT醒的更频繁, 可能时效性更好些. 在老式的多线程RPC实现中, 消息的读取分割和 epoll_wait 在同一个线程中运行, 类似上面的原因, ET和LT的区别不大.但在更高并发的 RPC 实现中, 为了对大消息的反序列化也可以并行, 消息的读取和分割可能运行和epoll_wait不同的线程中, 这时ET是必须的, 否则在读完数据前, epoll_wait会不停地无谓醒来.
不当的使用可能造成饥饿 Question:我看网上有人说ET需要配合robin list,这个和ET/LT没什么关系吧
[1] 简单来说就是对 epoll_wait 返回的 fd 不要一直读,如果这个 fd 有大量数据,就会导致其他 fd 的饥饿,正确做法是搞一个类似 round_robin 的机制去循环读所有fd
惊群问题 如果多线程阻塞在同一个fd上是会有惊群问题的,一种想法是,每个线程对应单独的一个epfd,其中一个线程专门负责accept,accept后的连接epoll_ctl到其他线程的epfd,可以避免此问题
[4]中提到的另一种做法是每个线程对应一个epfd,都监听listenfd,根据上文的源码分析,listenfd事件到来后是会发生惊群的。对于大量连接到来的情况,为避免全连接队列单线程通过accept消费的速度跟不上,使用多线程监听listenfd并消费是有理由的,但还是,要考虑惊群问题,Linux 4.5开始epoll_ctl支持 EPOLLEXCLUSIVE 选项解决此问题,摘录一部分(但是为什么是at least one……)
[9] If the same file descriptor is in multiple epollat of the epoll instances that did specify
TODO 看到文档上说 EPOLLEXCLUSIVE 可以和 ET 选项一起用,epoll默认是LT,意思是LT也是可以一起用的吧?https://wenfh2020.com/2021/11/20/question-epollexclusive/
Question: accept是线程安全的吗?https://stackoverflow.com/a/5124450/8454039
为什么使用红黑树?
需要判断fd是否已经正在监听,需要较高的查询效率,select以空间换时间,
若fd不存在则需要插入,也需要考虑插入复杂度
红黑树兼顾了插入、查询效率与树的旋转次数
如果读完一个ET返回的socket,但在调用epoll_wait前,来了新的数据,且调用epoll_wait后不再来新数据(假设必须要我们根据这条数据回复后对方才会发新数据),是否会有liveness问题? 不会的,没有人在 epoll_wait 只是影响 socket 回调不会调用 wakeup 通知阻塞方,而 ctl poll 时添加的 epi 还是在的,并不影响将epi添加到 ready list 的过程。因此即使中间有较短的时间不阻塞在 epoll_wait 但是来了数据,调用 epoll_wait 的时候由于 ready list 非空,还是会走到 poll,拷贝回用户空间,正常返回的,并不会hang住
为什么在边缘触发的epoll函数中要使用非阻塞fd? 对于 connfd
对于listenfd
LT与ET的epoll例子https://gist.github.com/liumuqi/04dc92629e322a4613a4610afe786818
TODO 关于非阻塞的想法,推荐扩展阅读高性能网络通信库中为何要将侦听 socket 设置成非阻塞的? one thread one loop 思想
拓展阅读 其实还没来得及读[知乎回答] Nginx为啥使用ET模式Epoll?
参考文章(epoll)
epoll边缘触发模式 [内核源码] epoll 实现原理 [内核源码] epoll lt / et 模式区别 [知乎回答] socket的任意event都会导致epoll_wait的惊群效应吗? epoll的边沿触发模式(ET)真的比水平触发模式(LT)快吗?(当然LT模式也使用非阻塞IO,重点是要求ET模式下的代码不能造成饥饿) 如果这篇文章说不清epoll的本质,那就过来掐死我吧! (2) epoll的使用实例 Is it possible (and safe) to make an accepting socket non-blocking? epoll_ctl(2) — Linux manual page
Reactor 与 Proactor Reactor 篇幅较短,就不新写一篇了
单Reactor单线程,同一个线程既负责阻塞在epoll_wait上,也负责事件到来后的处理
1 2 3 4 5 6 7 8 9 10 while True :for fd in fds: if fd == listenfd:else :
单Reactor多线程:Reactor线程只处理连接事件和读写事件,业务处理交给线程池处理[2]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 while true:for fd in fds: if fd == listenfd:else :class Task : @Override def run (Runnable r ):
主从Reactor多线程:认为accept连接比处理数据ready(准备好被读)要重要,因此单独一个线程只处理listenfd,accept后加入其他线程的epfd,其余逻辑同 单Reactor多线程
Proactor TODO 听说是基于AIO的
参考文章(Reactor与Proactor)
Reactor模式 Reactor线程模型 - 每天晒白牙的文章 - 知乎
![ref [3]](https://raw.githubusercontent.com/vicety/Images/master/images1771657-20200402205610896-733975945.png)
![ref [3]](https://raw.githubusercontent.com/vicety/Images/master/images1771657-20200402205717703-646415732%20(1).png)
![ref [3]](https://raw.githubusercontent.com/vicety/Images/master/images1771657-20200402205650773-1956018427.png)
![ref [3]](https://raw.githubusercontent.com/vicety/Images/master/images2021-12-31-12-44-05.png)
![ref [6]](https://pic2.zhimg.com/80/v2-5ce040484bbe61df5b484730c4cf56cd_1440w.jpg)